

ine 5376/79
Reconhecimento de Padrões
3. Técnicas Subsimbólicas: Redes Neurais
![]()
Parte I:
3.1. Filosofia
Geral da Aplicação do Raciocínio Subsimbólico
a Padrões: Redes Neurais Aprendendo Dados, Classificadores e Agrupadores
3.2. O
Simulador SNNS - Stutgarter Neural Network Simulator
3.3. Classificadores:
Usando Aprendizado Supervisionado para Reconhecer Padrões
Parte II:
3.4. Desenvolvimento de Aplicações: Usando Aprendizado Supervisionado
Parte III:
3.5. Agrupadores:
Usando Aprendizado Não Supervisionado para Organizar Padrões
3.5.1. O
Modelo de Kohonen e Quantização de Vetores
3.5.2. O
Modelo ART: Teoria da Ressonância Adaptativa
Parte IV:
3.6. Explorando
Dados Agrupados em Redes
3.6.0. O que aprende uma Rede de Kohonen ?
3.6.1. Qualidades Matemáticas do Modelo de Kohonen
3.6.2. Técnicas
de Exploração de Dados Agrupados em Redes
3.6.3. Qual é o objetivo
de KoDiag ?
3.6.4. Como funciona KoDiag ?
3.6.5. Utilizando
Redes de Kohonen para a coordenação visumotora de um braço
de Robô
3.6.6. Referências
3.6.
Explorando Dados Agrupados em Redes
3.6.0. O que aprende uma
Rede de Kohonen ?
Vimos até agora que:
- uma Rede de Kohonen é inspirada na forma como se supõe que redes neurais naturais aprendem e
- o modelo originou-se a partir das pesquisas anteriores de Teuvo Kohonen em Análise de Componentes Principais e Quantização de Vetores.
Na prática, uma rede
de Kohonen toma um conjunto de dados em um espaço de dados V qualquer
e os representa de forma discretizada através de um neurônio
(e eventualmente sua vizinhança) no espaço de um Mapa Auto-Organizante
A. Esta transformação de um espaço de representação
para outro é denominada mapeamento f,
podendo ser representada por:
![]()
A condição para que este mapeamento seja uma boa representação do espaço vetorial é que:
![]()
onde W é um vetor
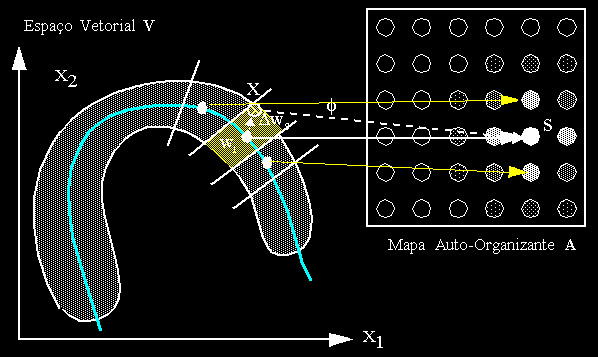
de pesos da rede A. Este mapeamento está ilustrado na Figura abaixo:
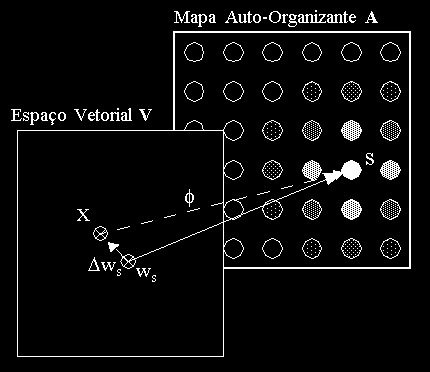
O espaço vetorial V é um espaço qualquer com a dimensionalidade do número de variáveis de um padrão X desse espaço. O vetor de pesos ws do neurônio vencedor S pertencente a A representa uma aproximação da função de mapeamento f que associa pontos do espaço vetorial V a neurônios em A. Dws é o erro dessa aproximação representado no espaço vetorial V.
Com isso, vimos como ocorre o mapeamento de entre o espaço vetorial e o espaço do Mapa Auto-Organizante da rede de Kohonen.
Supondo agora, que os dados em V possuem uma distribuição d qualquer, como é gerada a função de mapeamento f de forma a refletir esta distribuição ?
3.6.1. Qualidades Matemáticas do Modelo de Kohonen
Existem várias interpretações matemáticas da forma como uma rede de Kohonen aprende e de como devemos interpretar o mapeamento f gerado após o aprendizado da rede. Helge Ritter em sua tese de doutorado (Univ. de Munique, 1988) analisou em detalhe ambos. Nós vamos reproduzir aqui, omitindo os detalhes matemáticos, a sua interpretação da representação.
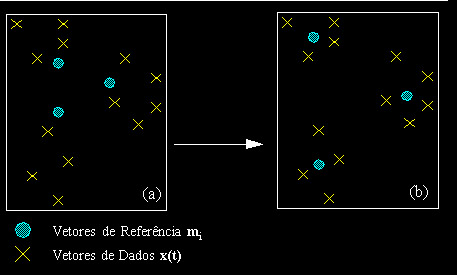
O conceito básico de representação em uma rede de Kohonen baseia-se na idéia de Componentes Principais. A Análise de Componentes Principais é uma técnica de análise de distribuição de dados onde se procura encontrar vetores de referência que representem de uma forma mais ou menos adequada conjuntos de vetores de uma distribuição de dados. Possui utilidade em mineração de dados e para decifrar códigos baseados em índices. A figura abaixo dá um exemplo de três vetores de referência miencontrados para aproximar uma distribuição de dados dividida em grupos.
Figura: Representação
de agrupamentos de dados expressando uma função x(t) em um
espaço n-dimensional qualquer através de vetores de referência
mi
O que uma rede de Kohonen
representa após o aprendizado pode ser considerado como uma generalização
dessa idéia.
Se nós observarmos uma distribuição de dados representando, por exemplo, todos os pares de valores de duas variáveis x1 e x2 que pertençam à categoria cj, poderemos ter um scatter plot como mostrado em (a) ou em (b) na figura abaixo, dependendo de como os dados se distribuem
Figura: Duas distribuições
de dados e suas componentes principais
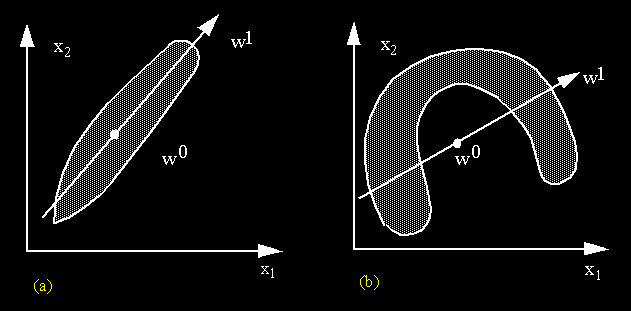
Podemos representar a componente
principal desta distribuição de dados através de um
único ponto w0 no espaço vetorial, que representará
exatamente o centro de massa da distribuição, ou através
de um vetor w1 que representa o eixo principal da distribuição,
indicando a sua tendência. Isto pode ser realizado através
de várias técnicas estatíticas, entre outras pela
Análise Fatorial, utilizada quando a nossa distribuição
de dados representa várias classes.
| Nota 1: Se a distribuição é conhecida, podemos calcular w0 usando exatamente o método de cálculo do centro de massa da Física, atribuindo uma massa qualquer, não nula, a cada um dos pontos do conjunto. |
| Nota 2: Das mesma forma, se a distribuição é conhecida, podemos utilizar o método de cálculo do eixo de massa principal da Física para obter w1. |
O problema de uma representação deste tipo ocorre quando temos uma distribuição de dados como em (b). Numa situação como essa, o centro da distribuição é um ponto em V que não pertence à distribuição e o eixo principal da distribuição é uma descrição muito pobre e falha do real comportamento desta. É o caso de distribuições de dados com tendências não-lineares, que nós já abordamos no capítulo 1, quando falamos de Nearest Neighbour.
Para representarmos adequadamente uma distribuição de dados como a representada em (b) necessitamos de uma representação não-linear da distribuição, dada por uma curva principal da distribuição, como é mostrado na Figura abaixo.
Figura: Curva Principal
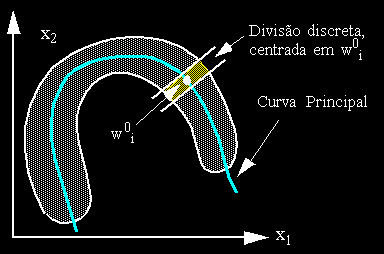
O cálculo exato de uma curva principal, porém, pode ser um processo matemático extremamente custoso, envolvendo interpolação polinomial ou outra técnica.
Quando discutimos Nearest Neighbour, no capítulo 1, e algoritmos que o utilizam, como IBL, no capítulo 2, vimos que existe a possibilidade de se aproximar um mapeamento de uma distribuição deste tipo através da divisão desta área curva em pedaços discretos, representados através de um conjunto de protótipos w0i. Isto está muito bem exemplificado pela facilidade com que IBL representa o problem ada espiral exatamente implementando esta técnica. Para gerarmos um conjunto de protótipos w0i deste tipo, porém, é necessário que a distribuição seja conhecida. Isto é fácil, quando temos, de antemão, associada a cada padrão, a sua categoria. Mas como proceder quando não conhecemos a distribuição dos dados nem quais classes existem ?
É aqui que a utilização de Redes de Kohonen se torna interessante: Helge Ritter demonstrou que uma rede de Kohonen aprende exatamente uma representação não linear discretizada deste tipo, sem necessidade de que se forneça de antemão as classes a que pertence cada padrão, realizando uma espécie de Análise Fatorial Não-Linear Discretizada. O resultado do processo de aprendizado, quando a convergência ocorreu adequadamente, é um mapeamento de subconjuntos da distribuição de dados a neurônios específicos da Rede A, que passam a fungir como protótipos para esses subconjuntos. Regiões vizinhas da distribuição são mapeadas para neurônios vizinhos no mapa de Kohonen A. O mecanismo de escolha do vencedor, similar a idéia do Nearest Neighbour, é o que garantre a não-linearidade da capacidade de representação da rede depois de treinada, agindo como uma função limiar, intrinsecamente não-linear, que determina as fronteiras entre cada subárea (subvolume) da distribuição mapeada. Isto pode ser visto na figura abaixo, onde uma classe é representada por um agrupamento (cluster) de neruônios em torno do vencedor S. O vencedor S representa com a maior aproximação o padrão X apresentado à rede..
Figura: Representação
discretizada de uma distribuição não-linear de padrões
aprendida por uma rede de Kohonen segundo Ritter.
3.6.2. Técnicas de Exploração de Dados Agrupados em Redes
Apropriedade estrutural das redes de Kohonen que vimos até agora coloca a pergunta: Não podemos de alguma forma aproveitar o fato de as redes de Kohonen estruturarem e organizarem topologicamente a informação aprendida ?
A resposta a essa pergunta é sim. Ao contrário das redes-BP, que necessariamente têm de ser encaradas como classificador de caixa-preta, as informações (e as abstrações) aprendidas por uma rede de Kohonen podem ser exploradas após o treinamento da rede e utilizadas das mais variadas formas.
Para finalizar este capítulo, vamos ver duas aplicações de redes de Kohonen.
A primeira delas se refere à utilização da informação contida em uma rede de Kohonen para guiar a busca de dados ainda desconhecidos que tenham a mais forte relação com um contexto atual de informação incompleta. Na verdade, trata-se da utilização de uma rede de Kohonen treinada como uma máquina de inferência neural que guia um processo de busca no sentido de se seguir pelo menor caminho na árvore de busca. Este trabalho foi realizado por nós no início da década de 1990 e apresenta uma solução para o problema de se explorar o espaço de possíveis soluções de maneira eficiente utilizando-se redes neurais.
A segunda é uma aplicação
de treinamento de um braço-robô desenvolvida por Helge Ritter
em 1989, onde se utiliza uma terceira camada de saída para uma rede
de Kohonen, que controla um braço-robô de forma a que se mova
para um ponto visualizado fornecido como dado de entrada. Esta não
é propriamente uma aplicação de reconhecimento de
padrões pura, mas mostra como extender uma rede de Kohonen através
de uma camada de saída, aspecto pouco comentado na literatura.
Utilizando Mapas Auto-Organizantes
como Máquinas de Inferência: KoDiag
No início da década de 1990 foi desenvolvido, pelo grupo de Sistemas Especialistas de Kaiserslautern, um sistema híbrido, denominado KoDiag [RW94, RW93, Wan93, RWW92, WR92], para diagnóstico baseado em casos utilizando uma Rede Neural de Kohonen modificada para dinamicamente atribuir pesos a atributos em função do contexto do problema e, assim, também realizar diagnóstico por meio do levantamento dirigido de atributos para o novo caso.
Para a implementação
de KoDiag foi utilizado o princípio do mapeamento topológico
da rede neuronal de Kohonen para o armazenamento de casos: casos mais similares
são armazenados em áreas topologicamente próximas
na rede. KoDiag utilizou pela primeira vez uma representação
não simbólica para a base de casos, que era aprendida pela
rede e ficava armazenada na mesma de forma sintética.
KoDiag utiliza a base de
casos de PATDEX [Wes91, Wes93] para o treinamento da rede neural. Os casos
são codificados como padrões especiais, e são representados
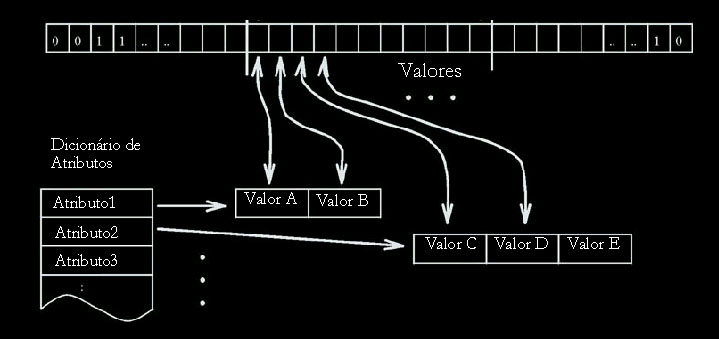
de forma explícita: variáveis, valores de variáveis
e diagnóstico. Dessa forma, o padrão de treinamento possui
3 partes: a primeira representa todas as variáveis do sistema; a
segunda, todos os possíveis valores dessas variáveis; e a
terceira, todos os diagnósticos. Dessa forma, um caso a ser treinado
é representado com dois valores para cada variável: um para
indicar a existência da mesma e outro para indicar seu valor.
Figura: KoDiag - no alto
é mostrado o padrão de treinamento. No diagnóstico,
somente a primeira parte era utilizada. Abaixo, o agrupamento ativo após
apresentação do caso atual [RW94]
KoDiag podia realizar aquisição incremental dirigida de dados para diagnóstico com a apresentação de dados incompletos da situação atual. Caso a informação não bastasse para o diagnóstico, o agrupamento de neurônios ativado por esta apresentação era analisado e o valor da variável ainda desconhecida mais fortemente correlacionada a este agrupamento era solicitado para ser levantado pelo usuário. Um exemplo de um padrão em PATDEX pode ser visto abaixo:
Código Smalltalk descrevendo um caso de defeito em uma máquina CNC utilizado por KoDiag
PortableCase
newCase: #Toolarm10
withEnvironment: #(#(#IoStateIN32
#logical0) #(#Code #I41)
#(#ToolarmPosition
#back) #(#IoStateOUT30 #logical0)
#(#IoStateOUT28
#logical1) #(#Valve21Y2 #switched)
#(#IoStateIN37
#logical1) )
describes: #IoCardFaultAtIN32i59
KoDiag é considerado um sistema de Raciocínio Baseado em Casos, em contraste com outros sistemas que também utilizam a codificação de casos em redes neurais, por utilizar uma interpretação autônoma passo a passo dos dados aprendidos na rede e guiar o usuário de forma inteligente no processo de levantamento de dados.
3.6.3. Qual é o objetivo de KoDiag ?
O ponto de partida para o desenvolvimento de KoDiag (Diagnóstico com Redes de Kohonen) foi a necessidade de se possibilitar o levantamento incremental de variáveis de um problema em uma situação de diagnóstico descrita como um padrão composto por pares atributo-valor: em muitas situações onde é necessário efetuar-se um diagnóstico de um problema não se possui de antemão valores para todas as variáveis do problema e tampouco todas as variáveis são necessárias para se determinar o diagnóstico correto para todas as situações.
Um exemplo é o domínimo de aplicação-exemplo de KoDiag: Diagnóstico de falhas em tornos de comando numérico:
- O estado de um torno CNC pode ser descrito por uma quantidade bastante grande de variáveis, como por exemplo a temperatura do óleo em diversas partes hidráulicas, o estado de diversos fusíveis, a mensagem de erro sinalizada no display de comando, o estado de desgaste da ferramenta de corte, etc.
- Quando um torno deixa de funcionar, dependendo do erro, apenas algumas dessas variáveeis terão relevância para se obter um diagnóstico correto da falha.
- Levantar o valor para todas é um processo desnecessário e custoso, uma vez que implica em tempo e, eventualmente, na necessidade de se desmonatr partes do torno ou de se realizar testes complexos para levantar o estado de uma peça ou parte mecânica.
- Partindo-se de um conjunto de variáveis iniciais, como por exemplo o código de erro mostrado pela máquina, é importante guiar o processo de levantamento de valores para as outras variáveis cujo valor ainda é desconhecido de maneira a otimizar o processo de busca de um diagnóstico. Para isso é preciso encontrar um caminho mínimo no espaço de pares variável-valor de maneira e levantar apenas os valores da variáveis relevantes ao contexto de falha atual e evitar levantar valores para variáveis desnecessárias, como por exemplo o estado do fusível da fonte de alimentação em uma situação onde o óleo de um componente hidráulico superaqueceu.
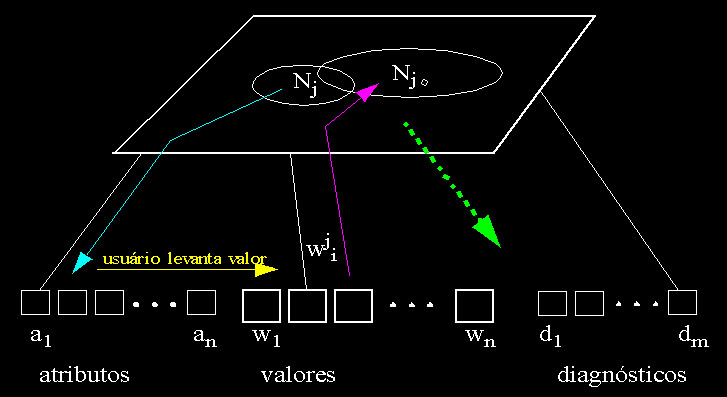
Em muitas situações, porém, a relevância de variáveis para contexto é desconhecida e precisamos de uma técnica capaz de agrupar as informações de forma a representar esses contextos. A rede de Kohonen é ideal para isso pois possibilita a exploração da informação codificada na rede através da:
- apresentação incremental de padrões incompletos, que são considerados como o contexto atual ,
- da exploração da informação da rede, tomando-se os neurônios ativados por este contexto e seguindo-se os pesos de volta para a camada de entrada e vendo-se com qual valor ainda desconhecido este contexto correlaciona masi fortemente.
KoDiag explora o fato de que uma rede de Kohonen mapeia valores de variáveis a contextos representados por grupos de neurônios na rede ativados por um padrão incompleto de forma a possibilitar o levantamento dirigido de novas informações.
A codificação de informação em KoDiag funciona da seguinte forma:
- Cada padrão é constituído de três partes: diagnóstico, variáveis, valores de variáveis.
- Para cada diagnóstico há um neurônio de entrada
- Para cada variável representando uma parte da máquina responsável por uma falha, há um neurônio de netrada.
- Para cada valor que essa variável pode assumir há também um neurônio de entrada. Para variáveis de domínios contínuos, discretiza-se o domínio em faixas de valores.
O processo de diagnóstico, depois de treinada a rede, funciona então da seguinte maneira:
- É apresentado à rede um padrão incompleto inicial, contendo apenas os pares variável-valor capazes de serem levantados de forma fácil, por exemplo: a mensagem de erro emitida pela máquina e o fato de o óleo em um mancal estar superaquecido.
- Este contexto inicial é propagado pela rede e observa-se quais neurônios respondem a ele com uma ativação mínima. Este é o conjunto dos ActiveNeurons.
- Propagamos a ativação destes neurônios de volta para a parte dos diagnósticos da camada de entrada usando os pesos das conexões existentes. Se há um neurônio de diagnóstico que obteve ativação acima de um limiar mínimo e ao mesmo tempo diferente o suficiente dos outros, consideramos que o contexto foi suficiente para se chegar a um diagnóstico inequívoco e paramos.
- Se isto não acontece, propagamos a ativação dos ActiveNeurons de volta para a parte das variáveis da camada de entrada usando os pesos das conexões existentes. Buscamos o neurônio representando uma variável cujo valor ainda é desconhecido que tenha obtido a maior ativação. Este é um neurônio que durante o treinamento foi associado ao contexto atual de forma forte.
- Levantamos o valor da variável representada este neurônio, detalhando o nosso contexto. Este par atributo-valor é então apresentado isoladamente à rede.
- Determinamos o conjunto de nerurônios do mapa de Kohonen ativados por este par, que é denominado ChosenNeurons. Estes são os neurônios do mapa associados a este contexto atributo-valor independentemente dos outros valores que o acompanham.
- Realizamos a intersecção entre o conjunto anterior, ActiveNeurons e os ChosenNeurons, levando ao novo conjunto de ActiveNeurons, cujo tamanho é bastante menor. Este procedimento de redução progressiva do conjunto de neurônios do mapa considerados garante a convergência do processo.
- Novamente propagamos a ativação dos ActiveNeurons para a parte de diagnóstico da camada de entrada, retornando ao passo 3. O processo termina quando o teste do passo 3 for satisfeito ou os ActiveNeurons representarem um conjunto vazio.
KoDiag foi testado com o mesmo conjunto de daods do sistema PATDEX, um sistem ade RBC estado-da-arte na época e os resultados obtidos foram bastante similares, tanto em termos de levantamento de variávesi quanto de resultados de classificação em função de perda de informação.
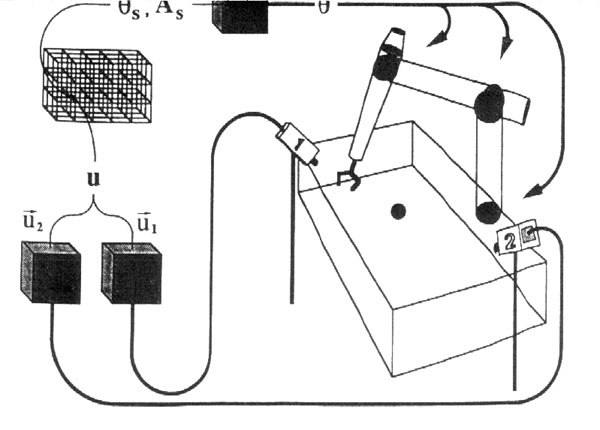
3.6.5. Utilizando Redes de Kohonen para a coordenação visumotora de um braço de Robô
Motivação: simulação das cartas motoras encontradas em cérebros de mamíferos utilizando uma rede de Kohonen tridmensional com uma camada extra de saída representando os comandos de movimento do braço-robô.
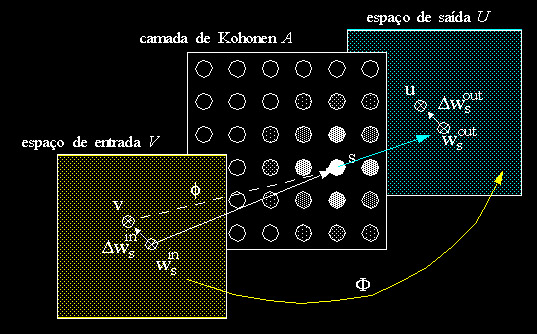
Técnica: Modelar uma projeção F : V -> U de um espaço sensorial V em um espaço de comandos motores U.
a) criar uma projeção f dos estímulos sensoriais V em uma carta tridimensional A
b) criar uma projeção da carta em um espaço de comandos motores U.
Figura: Desenho da
simulação utilizada por Helge Ritter

O modelo geral da projeção gerada pode ser visto na próxima figura. O objetivo é utilizar-se dois mapeamentos: um entre a camada de entrada e a de Kohonene outro entre camada de Kohonen e a de saída.
Figura: Mapeamento esperado
Algoritmo geral de treinamento:
- Registre a próxima ação de controle (v, u)
- Vencedor: calcule a posição na carta s := fw(v) que corresponde ao mapeamento do estímulo visual v na carta.
- Execute um passo de treinamento: IN
- Execute um passo de treinamento: OUT
- retorne a 1
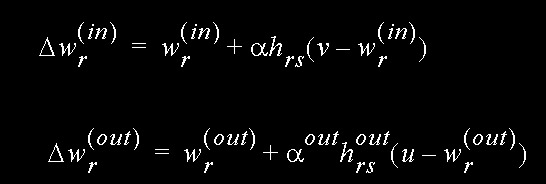
Estrutura da simulação para os movimentos do braço do robô:
- Posição do objeto dada por um vetor 4-dimensional
- Posição do braço do robô dada por um conjunto de 3 ângulos das juntas do braço.
Figura: Estrutura
da simulação para os movimentos do braço do robô
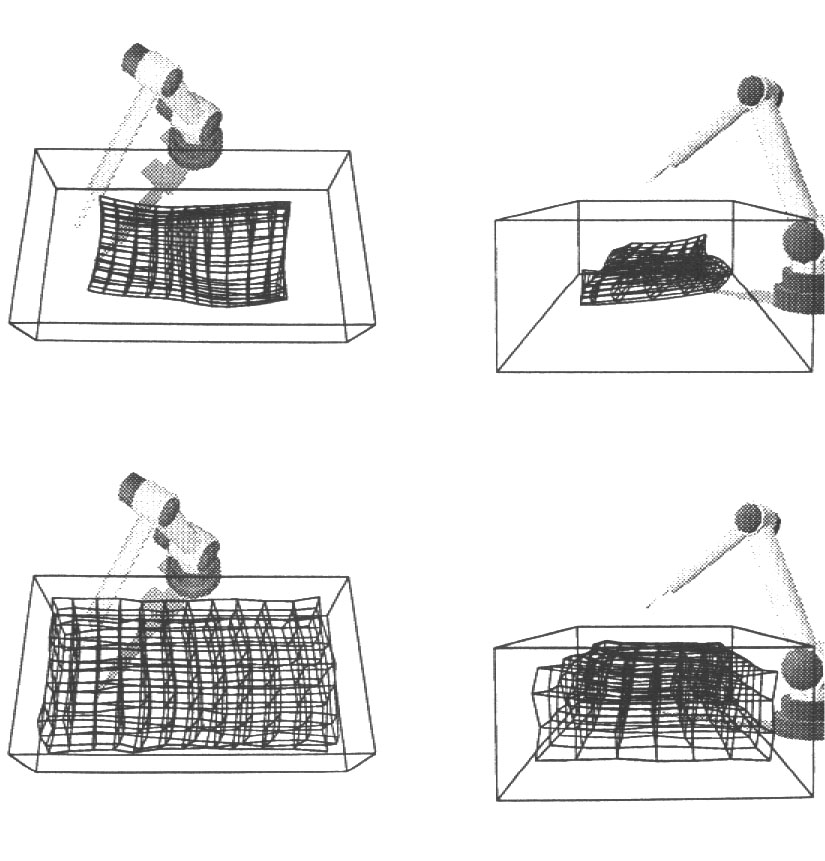
Resultados do treinamento podem ser vistos na próxima figura: com o passar do tempo a rede vai aprendendo a configuração tridimensional do espaço de movimentação do braço-robô e cada ponto do espaço na rede tridimensional é mapeado a um conjunto de ângulos das juntas do braço robô na camada de saída que movimenta o braço para aquela posição.
Figura: Treinamento
a) Espaços de Entrada e de Saída ao Início do Treinamento

b) Organizaçlão gradual da rede no espaço de saída durante o treinamento segundo Ritter
- [Koho88] Kohonen,Teuvo: Self-Organization and Associative Memory, Springer, 1988 (2. edition)
- [KR89] Kohonen,T., Ritter, H.; Self-Organizing Semantic Maps, Biol. Cybern., 61, 241-254, (1989)
- [RW93] J. Rahmel, A. von Wangenheim. The KoDiag System: Case-Based Diagnosis with Kohonen Networks. In Proceedings of the I International Workshop on Neural Networks Applications and Tools, Liverpool, IEEE Computer Society Press, 1993.
- [RW94] J. Rahmel, A. von Wangenheim. KoDiag: A Connectionist Expert System. In Proceedings of the IEEE International Symposium on Integrating Knowledge and Neural Heuristics, Pensacola, Florida, 1994.
- [RWW92] J. Rahmel, A. von Wangenheim, S. Wess. KODIAG: Fallbasierte Diagnose mit KOHONEN Netzen. In Proceedings of the GI Workshop Fälle in hybriden Systemen, Germany, 1992.
- [Wan93] A. von Wangenheim. Fallbasierte Klassifikation mit Kohonen Netzen. In Proceedings of the Workshop "Fälle in der Diagnostik", XPS-93, Germany, Februar 1993.
- [Wes91] S. Wess. PATDEX/2: Ein fallbasiertes System zur technischen Diagnostik. SEKI-Working Paper SWP91/01, Department of Computer Science, University of Kaiserslautern, Germany, 1991.
- [Wes93] S. Wess. PATDEX - Inkrementelle und wissensbasierte Verbesserung von Aehnlichkeitsurteilen in der fallbasierten Diagnostik. In Proceedings of the 2. German Workshop on Expertsystems, Germany, 1993.
- [WR92] A. von Wangenheim, J. Rahmel. Fallklassifikation und Fehlerdiagnose mit Kohonen-Netzen. In Proceedings of the Workshop "Ähnlichkeit von Fällen", Universität Kaiserslautern, Germany, 1992.
Implemente você mesmo
a estratégia de guia de diagnóstico do modelo KoDiag utilizando
os dados de animais de Kohonen e Ritter, vistos na aula anterior, extendendo-os
de forma a que contenham todo o set de dados: tando as características
dos animais como a "classe" de cada vetor de características. Dessa
forma você terá padrões de treinamento de no mínimo
23 entradas. Para tal, treine uma rede de Kohonen usando o SNNS de forma
a que ela prenda as distribuições dos animais e gere o arquivo
em "C" descrevendo esta rede. A seguir, utilize este código C e
extenda-o permitindo que as ações de busca descritas acima
sejam realizadas. Teste apresentando dados incompletos de animais e utilize
a filosofia de guia de busca de KoDiag para decidir se você pode
realizar o diagnóstico assim mesmo ou se você precisa levantar
mais alguma característica e qual é esta característica
que precisa ser levantada.
|
The Cyclops
Project
German-Brazilian Cooperation Programme on IT CNPq GMD DLR |

