

ine 5376/79
Reconhecimento de Padrões
3. Técnicas Subsimbólicas: Redes Neurais
![]()
Parte I:
3.1. Filosofia
Geral da Aplicação do Raciocínio
Subsimbólico
a Padrões: Redes Neurais Aprendendo Dados, Classificadores e
Agrupadores
3.2. O
Simulador SNNS - Stutgarter Neural Network Simulator
3.3. Classificadores:
Usando Aprendizado Supervisionado para Reconhecer Padrões
Parte II:
3.4. Desenvolvimento
de Aplicações: Usando Aprendizado Supervisionado
Trabalho
de Reconhecimento Ótico de Caracteres
Parte III:
3.5. Agrupadores:
Usando Aprendizado Não Supervisionado para Organizar
Padrões
3.5.1. O
Modelo de Kohonen e Quantização de Vetores
3.5.2. O
Modelo ART: Teoria da Ressonância Adaptativa
Parte IV:
3.6. Explorando
Dados Agrupados em Redes
Área de Download (alguns destes recursos de aula possuem links também mais abaixo)
- Versão do SNNS em Java para Windows
- Java Runtime Environment completo que você precisa para o software acima
- Versão compilada do SNNS 4.2 para Linux (se você possue RedHat ou Conectiva instalado pode ter problemas para rodar pois a versão do Athena suprida com RedHat e seus clones é meio estranha. Teste estas opções: a) Mude a profundidade de seu vídeo para 8 bits ou b) Não carregue os arquivos de configuração dos exemplos, apenas as redes e os arquivos de treinamento.
- Versão do SNNS para SunOS ou Solaris: Os fontes do SNNS compilam sem problemas nas plataformas Sun. Acesse a homepage do SNNS e baixe os fontes. As bibliotecas do Athena podem ser baixadas para Sun em vários lugares.
- Arquivo .PAT em sintaxe SNNS dos 360 pontos da Espiral Dupla para treinamento
- Arquivo .PAT em sintaxe SNNS dos 360 pontos da Espiral Dupla para treinamento (Com Erro 15)
- Arquivo .PAT em sintaxe SNNS dos 360 pontos da Espiral Dupla para treinamento (Com Erro 30)
- Conjunto de arquivos .JPG e .RAW dos números normalizados
- Arquivo .PAT em sintaxe SNNS dos números para treinamento
3.4. Desenvolvimento de Aplicações Usando Aprendizado Supervisionado
Importante:
O texto abaixo está estruturado de forma a complementar o
assunto
visto em aula de laboratório. O material não pretende ser
auto-explicativo nem didaticamente autosuficiente: esta
seção
supõe que a aula a que ela se refere foi assistida pelo aluno e
serve apenas de referência.
3.4.1. Aprendizado de Conjuntos Intrincados
O conjunto de dados distribuído sob a forma de duas espirais duplas, como já foi dito anteriormente, é um conjunto clássico de teste para redes neurais. Vamos tentar avaliar a competência de todos so métodos que veremos nesta disciplina utilizando este conjunto de dados. Até agora você viu como técnicas simples como kNN e como métodos simbólicos que utilizam Nearest Neighbour, como IBL se comportam frente a este conjunto de dados. Nesta seção veremos como se comporta uma rede-BP frente ao mesmo conjunto de dados. O objetivo desta comparação é fornecer-lhe dados para avaliar a performance e adequação desta técnica.Para isto utilizaremos uma rede neural como mostra a figura abaixo. Esta rede está organizada em 3 camadas, possuindo apenas uma camada interna. A organização desta camada interna como uma matriz é somente um subterfúgio gráfico para fazer a rede caber na janela do simulador, a posição de um neurônio nesta matriz, ao contrário do que ocorrerá mais adiante em redes de Kohonen, não possui nenhum significado.
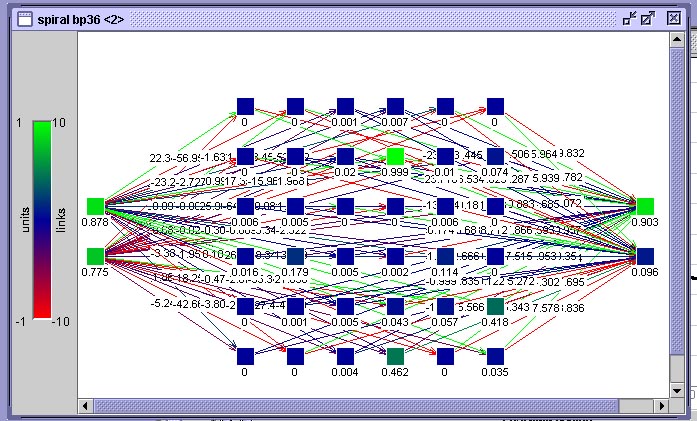
Rede-BP para teste do conjunto espiral dupla mostrada no visualizador de rede do SNNS
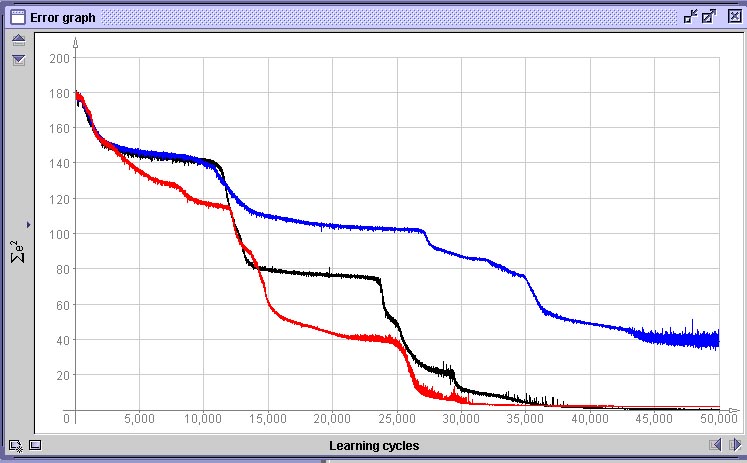
A próxima figura representa o gráfico de variação do erro E(w) durante o treinamento desta rede. A abcissa representa o número de épocas (ciclos sobre todos os 360 padrões) e a ordenada o erro global E(w) da rede. Nós interrompemos o treinamento em 42.000 épocas, o que para um conjunto de treinamento de 360 padrões, perfaz 15.120.000 iterações. Observe que o erro se reduz em “saltos”. Isto é comum em métodos de descida em gradiente e significa que o processo encontrou uma “ravina” na paisagem de gradientes e começou a descê-la até encontrar outro “platô”.
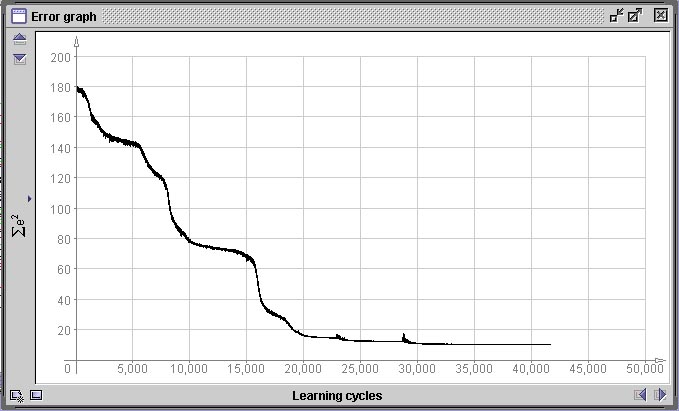
Gráfico do erro global E(w) da rede da figura anterior.
Decidimos abortar o treinamento em 42.000 ciclos pois o erro não apresentou mais redução significativa durante 20.000 ciclos, o que significa que a rede ou encontrou o máximo de fidelidade possível no mapeamento da função que desejamos que aprenda ou então que encontrou um mínimo local na paisagem de erro.Um mínimo local é um pequeno “vale” na paisagem de erro definida por E(w), mas que não contém o menor erro possível. Como as regiões ao redor de um mínimo local são regiões que possuem todas um erro menor e o método de descida em gradiente tenta sempre encontrar um novo conjunto de valores de pesos que reduza o erro e nunca um que aumente, a rede nunca sairá dalí. Mínimos locais são o maior problema que deparamos em métodos de descida em gradiente. Como o estado inicial do sistema é aleatório e a ordem de apresentação dos padrões também, o caminho que leva ao mínimo erro global pode passar por um mínimo local ou não, dependendo do acaso. Quando nos deparamos com um mínimo local onde a rede “encalhou”, a única opção que temos utilizando o algoritmo de rede-BP tradicional é a de reinicializar a mesma e treinar novamente desde o início. Ná próxima figura vemos três situações de gráfico de erro completamente diferentes geradas após 50.000 épocas pela mesmo rede com o mesmo conjunto de dados. Apenas foram geradas inicializações diferentes, porém com os mesmos parâmetros.
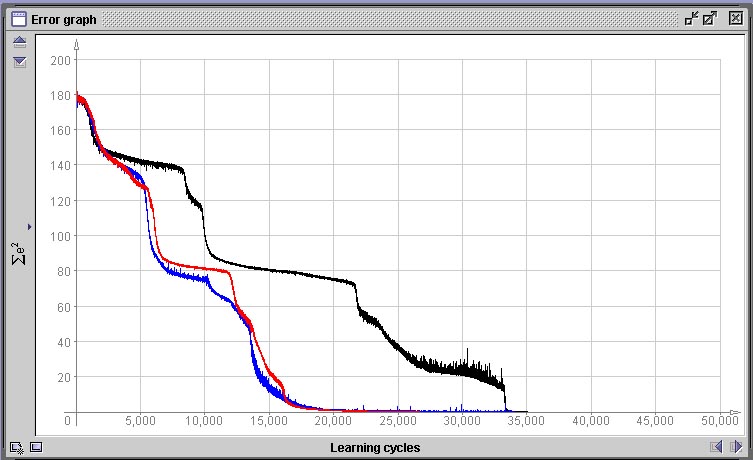
Comparação de variação aleatória de performance de treinamento em dependência da inicialização
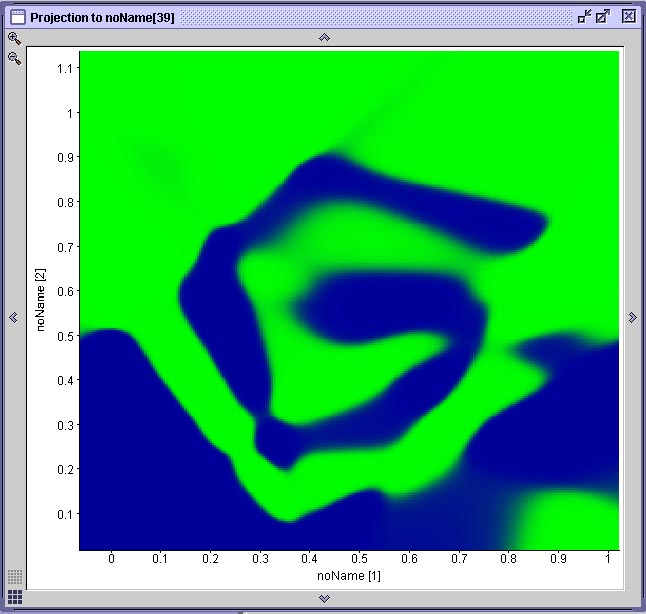
Nos três casos acima, apesar da performance de aprendizado ter sido bastante diferente, em nenhum dos três casos a rede encontrou um mínimo local e estacionou em um platô de erro constante. Todas as três redes atingiram um erro próximo de 0.Na figura abaixo vemos o resultado da projeção de duas superfícies de decisão geradas por duas das mostradas anteriormente. Cada projeção é gerada através de uma ferramenta do SNNS que permite associar-se graficamente dois neurônios de entrada a um de saída. O gráfico resultante mostra a ativação do neurônio de saída para todas as possíveis combinações de valores de entrada nos dois neurônios selecionados. No caso específico da espiral dupla, onde existem apenas dois neurônios de entrada e dois neurônios de saída, esta projeção corresponde à superfície de decisão gerada pela rede. Compare este resultado com a performance do algoritmo IBL, observando que cada rede que gerou este resultado teve de ser treinada durante 20 minutos em um computador com 512 MB de RAM e um processador AMD 1800+ e que o algoritmo IBL (1, 2 ou 3) toma uma fração de segundo para realizar a mesma coisa em um computador com essas especificações.
 |
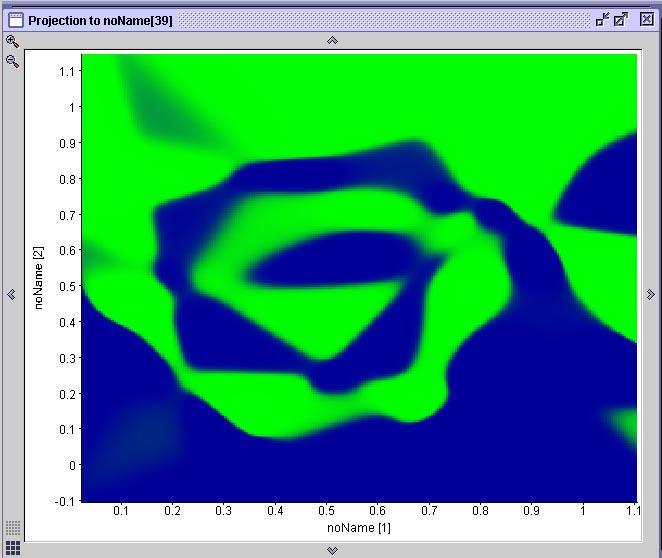 |
Duas projeções das superfícies de decisão geradas pelas redes anteriores
Observe que na rede (A) há uma área mapeada incorretamente. A rede (B) aprendeu a espiral com qualidade aceitável. A rede (A) é a primeira rede neural treinada, cuja treinamento foi interrompido em função de uma mínimo local. Aqui podemos observar que o mínimo local que a rede encontrou a impediu de aprender uma parte do problema, fazendo com que a superfície de decisão ficasse incompleta.3.4.2. Aprendizado de Conjuntos Intrincados Apresentando Erro
Para termos uma idéia como se comporta uma rede-BP nos casos onde existe algum erro nos conjuntos de dados, retomemos as nossas espirais geradas apresentando desvio aleatório de posição dos dados do conjunto de treinamento de até 15 e de até 30 pixel. |
 |
O resultado do
treinamento
de três redes com o conjunto de dados de treinamento com erro de
até 15 pixel pode ser visto abaixo. Observe que a
superfície
de decisão gerada (mostra a rede cuja curva de treinamento
está
em preto) é bastante boa. As curvas de treinamento mostram que
uma
das redes treinadas (curva em azul), além de mostrar um
comportamento
de aprendizado bastante ruim, com muitas oscilações,
provavelmente
vai cair em um mínimo local.
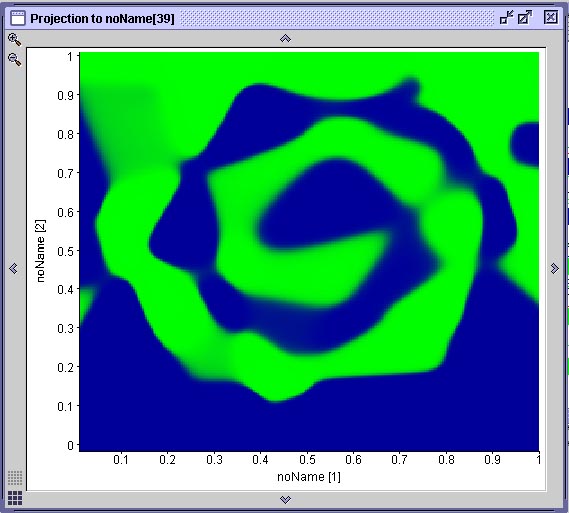
 |
Se utilizarmos o
conjunto
de treinamento gerado com erro de até 30 pixel, a qualidade do
aprendizado
deteriora bastante, como vemos na superfície de decisão
abaixo.
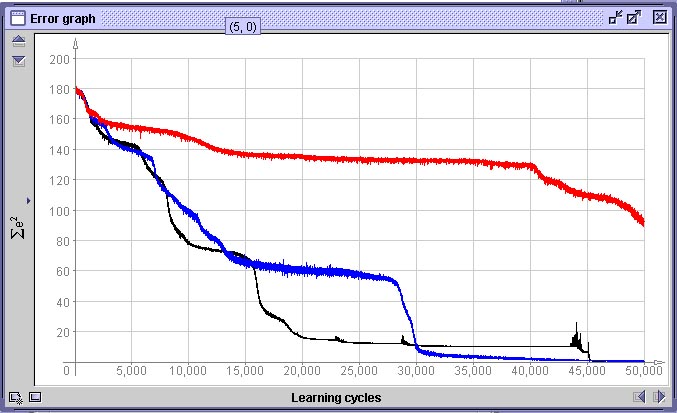
As curvas comparam a performance de uma rede treinada com dados com
erro
de 30 pixel (vermelho), erro de até 15 pixel e uma
treinada
com dados sem erro.
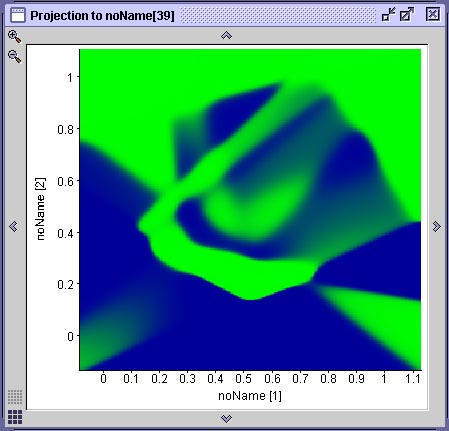 |
 |
Dados:
- Arquivo .PAT em sintaxe SNNS dos 360 pontos da Espiral Dupla para treinamento
- Arquivo .PAT em sintaxe SNNS dos 360 pontos da Espiral Dupla para treinamento (Com Erro 15)
- Arquivo .PAT em sintaxe SNNS dos 360 pontos da Espiral Dupla para treinamento (Com Erro 30)
3.4.3.
Uma Aplicação de Reconhecimento de Padrões
Simples:
Reconhecer CEPs em Cartas
Tarefas que
parecem mais
complexas do que a classificação de dados
sintéticos
como o da espiral dupla, são, muitas vezes, bastante mais
simples.
Um exemplo é o caso do reconhecimento ótico de caracteres
impressos.
Suponha um sistema
para
litura automática do CEP em cartas. O sistema pressupõe
que
o CEP foi batido à máquina. Nosso exercício aqui
pressupõe
também que os passos iniciais, onde o CEP deverá ser
identificado
na carta, recortado da imagem da carta e normalizado para uma mesma
resolução
(número de pixel) são realizados por um algoritmo que
não
interessa no momento (vamos vê-los mais tarde no capítulo
de processamento de imagens).
Um exemplo de um
conjunto
de números + hífem impresso por uma máquina de
escrever
e possíveis CEPs escritos com ela está abaixo.

Para criar um pequeno sistema de OCR (reconhecimento ótico de caracteres) vamos supor que a primeira linha do escaneado na figura anterior será nossa amostra para treinamento. Para preparar esta amostra para que uma rede neural possa aprendê-la temos de primeiramente seguir os seguintes passos:
- Decidir por uma representação. Neste caso vamos escolher representar os valores diretamente através de seus valores de pixel. Como a camada de entrada de uma rede-BP é unidimensional, vamos representar a matriz de uma imagem por linhas, cada linha ao lado da anterior.
- Aumento do contraste. As imagens da amostra (escaneadas com os tons de cinza do papel) são de baixa qualidade. Simplesmente aumentamos o contratste da imagem para tornálos mais visíveis.
- Redução da resolução. Se pretendemos representar cada algarismo pelos seus pixels, não podemos fazer isto numa resolução onde cada algarismo ocupa uma matriz 70x100 ou similar. Temos de realizá-lo de forma simplificada. Fá-lo-emos inicialmente com uma matriz de aproximadamente 10x15.
- Normalização: Como os tipos da máquina de escrever são de tamanho diferente, escolhemos um tamanho-meta e “normalizamos” as imagens para este tamanho. O tamanho-meta será 10x15 pixel, significando 150 neurônios na camada de entrada da rede. Agora tomamos cada número, recortamos exatamente os pixeis não brancos e redimensionamos a imagem resultante para 10x15.
 |
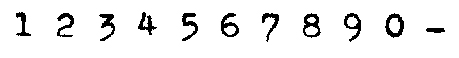 |
 |
Tudo o que temos de fazer ainda é criar arquivos de dados para treinamento da rede. Nós fizemos um método simples em Smalltalk que lê um arquivo de dados binário e incluios dados em um arquivo ASCII na sintaxe do SNNS. Como entrada para este método usamos um conjunto de dados gerado a partir das imagens acima salvando-as em formato .RAW (só bytes e mais nada) em um editor de figuras. A cada figura carregada neste método, associamos manualmente um valor de saída.
Agora podemos criar uma rede-BP no SNNS com 150 neurônios de entrada, 10 de saída e um número qualquer (no nosso exemplo: 30) na camada intermediária, como na figura abaixo:

Ativação
da camada de entrada ao apresentar-se um padrão
Na década de 1960 foi criado um conjunto de caracteres especialmente desenvolvido para ser utilizado com OCR. Ele existiu em várias versões e a versão mais conhecida e utilizada até hoje em muitos locais do mundo onde se pratica OCR em formulário é o fonte OCR-A, mostrado abaixo. Até um perceptron simples deveria ser capaz de reconhecer caracteres em OCR-A sem dificuldade. Você vai realizar este experimento. No seu trabalho você vai, além dos caracteres de máquina de escrever acima, treinar uma rede neural com OCR-A, disponibilizado em 10x15 abaixo. Esta rede neural vai ter várias arquiteturas e uma delas será um perceptron simples, sem camada intermediária. Funciona ?

Exemplo do fonte
OCR-A
especialmente desenvolvido na década de 1960 para reconhecimento
ótico. Na parte de cima da figura repetimos a
seqüência
de caracteres numéricos representada em um grid de pixels de
10x15
para cada caracter. Nesta resolução foram gerados os
dados
para a sua rede neural e que estão nos arquivos .raw abaixo.
3.4.4. Outra Aplicação: Determinação Automatizada do Grau de Malignidade (Gradação) de Tumores aplicada ao exemplo da gradação de tumores do grupo dos astrocitomas/glioblastomas (tumores cerebrais)
 Veja http://www.inf.ufsc.br/~awangenh/pathos.html
Veja http://www.inf.ufsc.br/~awangenh/pathos.html
3.4.5. Trabalhos
Passados em sala de aula.
Dados para os trabalhos:
- Conjunto de arquivos .JPG e .RAW dos números de máquina de escrever normalizados em 10x15
- Conjunto de arquivos .JPG e .RAW dos números em OCR-A normalizados em 10x15 (aqui em .rar)
- Arquivo .PAT em sintaxe SNNS dos números de máquina de escrever para treinamento
- Para os números em OCR-A você mesmo deverá gerar os arquivos .pat a partir dos dados .raw
3.4.6. Breve
Comparação
entre Redes-BP, redes-RBF e métodos simbólicos utilizando
Nearest Neighbour
Nesta
seção
realizaremos uma breve comparação entre redes-RBF e
redes-BP,
extraída de [Haykin] e um comentário nosso sobre
redes-RBF
e sua relação com Nearest Neighbour e métodos que
utilizam NN, como IBL*.
As redes-RBF e os
perceptrons
de múltiplas camadas treinados com algoritmo backpropagation
(redes-BP)
são ambos exemplos de redes feedforward não lineares
treinadas
através de aprendizado supervisionado, sendo aproximadores
universais.
Isto quer dizer, se existe uma função capaz de mapear o
conjunto
de vetores de entrada no conjunto de vetores de saída (classes)
desejado, este mapeamento é garantido ser possível de ser
aprendido, dispondo-se de memória e tempo de processamento
suficientes.
Esta
equivalência
garante que sempre existirá uma rede-RBF capaz de reproduzir o
comportamente
de uma rede-BP específica e vice-versa. As
diferenças
entre os modelos são as seguintes:
- Uma rede-RBF clássica terá sempre uma única camada interna (hidden layer), enquanto uma rede-BP pode ter várias.
- As redes-BP são homogêneas e todos os neurônios possuem o mesmo modelo, compartilhando a mesma função quaselinear de ativação, não importando em qual camada se encontram. Os neurônios de uma rede-RBF possuem funções de ativação diferentes, sendo que a camada interna possue geralmente uma função gaussiana e a camada de saída uma função linear (que pode ser a identidade). Isto significa que a camada interna de ma rede-RBF é não linear, mas sua camada de saída é linear. No rede-BP todas as camadas são não-lineares.
- A função de ativação dos neurônios da camada interna de uma rede-RBF calcula a distância euclideana entre o vetor de entrada e o centro daquele neurônio. A função de ativação de uma rede-BP calcula o produto interno do vetor de entrada pelo vetor de pesos daquele neurônio.
Em resumo, uma rede-BP tenta encontrar uma única função não-linear capaz de representar o problema sendo treinado, enquanto que uma rede-RBF realiza um conjunto de aproximações locais não-lineares (uma por neurônio interno) baseadas em distância euclideana e delimitadas por uma função gaussiana que sejam linearmente separáveis e possam ser representadas pela função de mapeamento linear implementada entre a camda interna e a camada de saída.
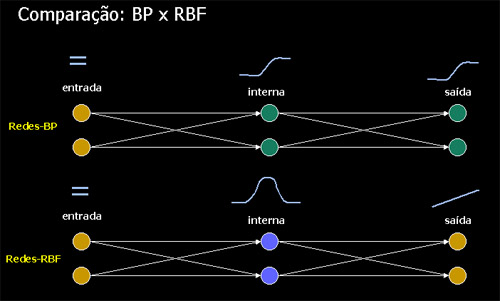
Visão
geral
da distribuição das funções de
ativação
em redes-BP e -RBF: Acima de cada camada está representado o
tipo
de função de ativação típico.
Considere agora o
seguinte:
Sabemos que métodos utilizando Nearest Neighbour, como os
algoritmos
da família IBL ou kNN realizam um mapeamento muito parecido com
a descrição das redes-RBF dada acima. A diferença
está no fato de que não existe uma
suavização
da distância euclideana através de uma curva gaussiana (ou
função similar). A não-linearidade que permite ao
modelo baseado em NN representar problemas complexos é
introduzida
pela heurística de limiar móvel dada pela regra de
escolha
do protótipo mais similar. Traduzindo em outras palavras, o
modelo
utilizado pelo algoritmo IBL, por exemplo, é um mapeamento local
não linear porque, apesar da distância euclideana
representar
um mapeamento linear, o fato de aplicarmos uma decisão
binária
ao resultado da nossa comparação de distâncias
(tomando
o protótipo mais próximo) representa uma
não-linearidade
similar ao de um limiar (threshold).
Sugerimos que
você
tome alguns problemas clássicos (espiral dupla, por exemplo) e
outros
com os quais você esteja familiarizado e realize uma
comparação
entre a performance de redes-RBF com várias topologias e a
performance
de vários modelos IBL, como IBL2, IBL3, etc. Qual a
diferença
no tempo de treinamento ? Qual a diferença na taxa de erros de
classificação
? Qual a tolerância a erros ? Acreditamos que os resultados que
você
vai obter vão lhe ensinar bastante sobre reconhecimento de
padrões.
3.5.
Agrupadores:
Usando Aprendizado Não Supervisionado para Organizar
Padrões
|
The Cyclops
Project
German-Brazilian Cooperation Programme on IT CNPq GMD DLR |

