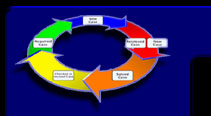

RBCReutilização e
Adaptação de
Casos
Uma das hipóteses básicas de sistemas de RBC é que problemas similares possuem soluções similares. Com base nesta hipótese, o critério a posteriori da utilidade de soluções passa a ser reduzido ao critério a priori da similaridade de descrições de problema. Esta forma de se proceder é justificada pela premissa de que, em muitas aplicações, a similaridade de definições de problemas implica a aplicabilidade da solução de um sobre outro.
A eficácia de enfoques baseados em casos depende essencialmente, portanto, da escolha de um conceito de similaridade adequado para o domínio de aplicação e a estrutura dos casos usada. Este conceito de similaridade deveria permitir a estimativa da utilidade de um caso com base na similaridade observada entre a descrição do problema atual e a contida no caso.
No cerne da definição do conceito de similaridade é preciso, portanto, que esteja a questão da determinação da utilidade do caso escolhido para a solução da problemática atual. A solução descrita em um exemplo de caso escolhido pode ser útil para um novo problema, caso ela:
- permita o solucionamento do problema atual de alguma forma;
- evite a repetição de um erro anterior;
- permita um solucionamento eficiente do problema, que seja mais rápido do que, por exemplo, utilizar uma heurística passo a passo para calcular uma solução;
- ofereça a melhor solução para o problema de acordo com um critério de otimalidade qualquer;
- ofereça ao usuário uma solução cuja lógica possa ser compreendida por ele.
Em linguagem
coloquial, similaridade
é entendida como sendo a correspondência ou
co-ocorrência
de atributos ou características. No contexto do RBC, esta
visão
simplista deve ser tomada de forma mais diferenciada.
As
aplicações
de sistemas de RBC e os objetivos que almejam atingir podem ser muitos
e variados. Alguns exemplos são:
- Pessoal de um Serviço de Atendimento ao Consumidor de um fabricante de impressoras pode usar um sistema de RBC de help desk para realizar o diagnóstico de um defeito descrito por um cliente, ao telefone, e indica soluções.
- Um viajante potencial pode usar um sistema de comércio eletrônico baseado em RBC, na Internet, para encontrar um pacote de viagem de acordo com as suas exigências.
- Um arquiteto pode utilizar um sistema de planejamento baseado em RBC para obter os primeiros esboços de um projeto de um prédio atendendo a um conjunto de requisitos.
Uma meta de recuperação explicitamente coloca o objeto a ser reutilizado, a finalidade de sua reutilização, a tarefa relacionada à reutilização, o ponto de vista específico e o contexto particular.
4.2. Indexação
Para que se possa
encontrar
casos similares na base de casos para um problema dado, temos de
definir
quais atributos usaremos para realizar a comparação entre
um caso e a situação presente.
Estes atributos,
utilizados
para a determinação de casos adequados para
comparação,
são denotados índices.
Assuma que, independentemente da representação de casos específica utilizada (veja Capítulo 4), um caso consista de um conjunto de entidades de informação. Uma entidade de informação (EI) é uma parte atômica de um caso ou descrição de problema. Por exemplo, em relação à representação de pares atributo-valor, cada atributo representa uma entidade de informação do caso.
Podemos então diferenciar as entidades de informação no âmbito de um caso de acordo com seu uso:
- entidades de informação utilizadas para a recuperação, também denotadas como índices;
- entidades de informação que provêm informação contextual ou de soluções do problema úteis ao usuário, mas que não são diretamente utilizadas para a recuperação, também chamadas de informações não-indexadas.
4.3. Metodologias de Indexação
No RBC temos de utilizar esruturas de indexação que nos permitam indexar um caso por 30 ou mais chaves secundárias e nenhuma chave primária e realizar a recuperação com base em um subconjunto dessas chaves. Técnicas mais comuns como árvores-B, árvores-B+ ou tabelas de hash são inadequadas para uma aplicação assim. Uma das estruturas de indexação que mais tem sido utilizada é a Árvore k-d. Uma árvore k-d é:
- Árvore binária para indexação multichave. Também chamada Árvore de Pesquisa Binária Multidimensional.
- Foi "redescoberta" pela Inteligência Artificial no início da década de 1990 como mecanismo de indexação de casos em Raciocínio Baseado em Casos.
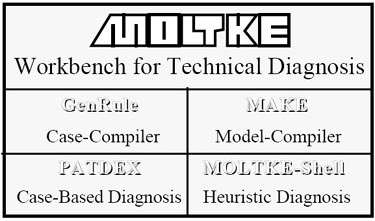
- Sistemas de RBC muito conhecidos como PATDEX (PATtern Directed EXpert System - o antecessor do CBR-Works e uma componente da bancada de IA MOLTKE [1][2]) e INRECA utilizaram esta técnica.
- Uma árvore k-d é uma árvore onde k é o número de chaves para cada registro. Assim, chamamos uma árvore com três chaves de árvore 3-d (tridimensional), etc.
- Cada registro em uma árvore k-d possui, além dos dados e ponteiros, um conjunto ordenado de k valores de chaves (v0,...,vk-1).
- Associado a cada nodo P está um discriminador DISC(P), que é utilizado para especificar qual chave da k-tupla v0,...,vk-1 será utilizada neste nodo para tomar uma decisão de ramificação.
- O filho à esquerda é chamado loson(P) e o à direita hison(P).
- Caminhamento e Inserção (nas folhas) são realizados seguindo-se a seguinte regra de decisão (dados Q = chaves do registro procurado ou registro a ser incluído e P = nodo):
- Se dois valores de chave são iguais, a decisão é tomada com base nos demais valores de chave na seguinte ordem (superchave):
- Se incluirmos o conjunto de registros com 3 chaves abaixo em uma árvore 3-d teremos a árvore mostrada abaixo:
Geralmente o discriminador é função da profundidade do nodo (resto da divisão da profundidade pelo número de chaves).
SE Kj(Q) <
Kj(P)
ENTÃO o registro Q está em loson(P)
SE Kj(Q) >
Kj(P) ENTÃO
o registro Q está em hison(P)
Sj(P) = Kj(P),Kj+1(P),...,Kk-1(P),K0(P),...,Kj-1(P)
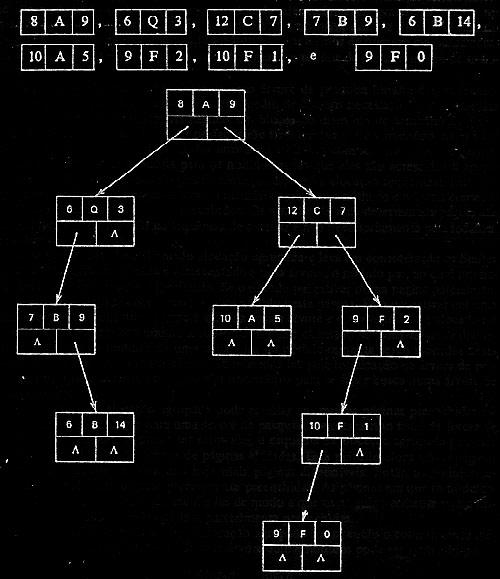
- A primeira decisão de ramificação (raiz) é tomada com base na chave primária (8), no nível 1 com base na segunda chave e no nível 2 com base na terceira chave. No nível 3 voltamos a usar a chave 0 como critério de decisão.
- Árvores k-d podem ser utilizadas diretamente para todos os 3 tipos de pesquisa: simples, com limites e booleana.
- O tempo médio de acesso a um registro não é pior do que o da árvore binária. Todas as características de tempo de pesquisa, complexidade, etc da árvore binária valem, no que diz respeito à pesquisa, também para a árvore k-d: O(1,4 log2 n).
- Inserção (não balanceada) de um nodo requer também tempo O(log2 n).
- Flexibilidade: Aplicável a qualquer tipo de aplicação onde se queira fazer recuperação de chaves secundárias ou recuperação multichaves.
- Gera árvores de profundidade extremamente grande.
- Inserção balanceada é extremamente cara.
- Rebalanceamento (apos várias inserções ou exclusões)
Solução: Pode ser resolvido através da paginação.
também extremamente caro.
- Boa técnica de indexação para arquivos somente com ou com muitas chaves secundárias (Ex.: bases de casos em CBR).
- Boa técnica para aplicações onde há poucas modificações.
- Utilização da árvore k-d como árvore de índices com paginação é sugerida para implementações em disco.
Sugestão para facilitar buscas booleanas: pelo menos uma subárvore com k níveis em cada página.
Material da Aula em PDF
|
The Cyclops
Project
German-Brazilian Cooperation Programme on IT CNPq GMD DLR |

