

INE 5443
2. Técnicas Simbólicas
2.1. Aplicando
raciocínio simbólico a padrões: Inteligência
Artificial aprendendo Dados
2.1.1. O que é aprendizado simbólico ?2.2. Classificação dos Métodos de Aprendizado
2.1.2. Brevíssimo Histórico do Aprendizado em IA
2.1.3. Como ver o aprendizado em RP ?
2.2.1. Forma de apresentação dos padrões a serem aprendidos2.3. O Aprendizado de Máquina Baseado em Instâncias
2.2.2. Processo de aprendizado
2.2.3. Forma de avaliação do aprendizado
2.2.4. Requisitos para o Reconhecimento de Padrões
2.4. IBL - Instance-Based Learning: Como Algoritmos Aprendem Simbolicamente
2.5. IBL2 e IBL3: Extensões do Modelo de AM
2.6. Discussão
2.7. Referências e links úteis
2.1.
Aplicando raciocínio simbólico a padrões:
Inteligência
Artificial aprendendo Padrões de Dados
Learning is making useful changes in the working of our minds.
Marvin Minksy, The Society of Mind
A capacidade de um sistema de realizar o Reconhecimento de Padrões de forma flexível e adaptável está intimamente associada à idéia de que um sistema de reconhecimento de padrões deve ser capaz de aprender as caracterísitcas e a distribuição dos padrões no espaço vetorial definido por um determinado domínio de aplicação e, por conseguinte, ser capaz de aprender como associar um determinado padrão à classe à qual pertence, ou, numa acepção mais extensa, ser capaz de aprender quais classes se encontram implícitas em um conjunto de padrões existente em um domínio de aplicação.
A integração com o aprendizado é uma das características mais importantes de vários campos da Inteligência Artificial tradicional que trabalham com informações organizadas como seqüências atributo-valor (padrões). Dentre estes podemos citar principalmente as áreas do Raciocínio Baseado em Casos (RBC) e do Aprendizado de Máquina (Machine Learning - ML - em inglês). Na realidade, a força motriz por detrás do RBC veio em grande parte da comunidade de pesquisadores em Aprendizado de Máquina, tanto que alguns autores consideram RBC como uma área de Aprendizado de Máquina.
A noção de aprendizado, portanto, não denota apenas um método particular de raciocínio, sem levar em consideração como os padrões são adquiridos, mas implica também em um paradigma de aprendizado automatizado (de máquina) que suporta o aprendizado sustentado através da atualização contínua da memória de descrições de situações apresentadas ao sistema (padrões ou casos). Em ambas as situações, tanto no RBC como no AM, temos a situação de que novo conhecimento é apresentado ao sistema sob a forma de padrões (que podem ser descrições de problemas e suas respectivas soluções no RBC ou simplesmente descrições de situações no AM).
2.1.1. O que é aprendizado simbólico ?
Podemos dividir a Inteligência Artificial de forma grosseira em IA Simbólica (ou Tradicional) e IA Subsimbólica (ou Coneccionista). As fronteiras entre estas duas categorias de IA, porém, não são muito claras, como veremos ainda nesta seção.
Na IA Simbólica trabalhamos com peças de informação onde cada elemento de informação possui um significado a ele associado (ou, no mínimo, associável). Falamos que cada dado possui um simbolismo. Na IA Simbólica trabalhamos com procedimentos lógicos e algoritmicos e um dos objetivos é o desenvovlimento de lógicas e de metodologias de representação do conhecimento de forma a possibilitar uma melhor manipulação dessas representações simbólicas.
Na IA Subsimbólica trabalhamos com dados "numéricos", onde nem sempre é possível associar-se um simbolismo claro a um dado específico no seu contexto de aplicação. Por exemplo, considere uma série temporal representando a flutuação das cotações de uma ação de uma empresa. A série como um todo possui eventualmente um simbolismo claro: "queda drástica e constante da cotação". Mas qual simbolismo devemos associar a uma flutuação que ocorreu ao meio dia de quarta feira ? No contexto de nossa manipulação simbólica desta informação, esta flutuação é apenas um número. Possui caráter subsimbólico. Na IA Subsimbólica utilizamos métodos numéricos para manipulação de grandes quantidades de dados (geralmente representados como padrões) com o objetivo de abstrair de suas caracteríticas subsimbólicas e gerar classificações ou raciocínios sobre estes dados. O exemplo mais clásico da IA Subsimbólica (e porisso é chamada também de Coneccionista) são as Redes Neurais. Ao contrário da IA Simbólica, onde todos os passos de raciocínio são explícitos e passíveis de verificação, na IA Subsimbólica existe a tendência ao desenvovimento de métodos de caixa preta, onde a representação do conhecimento está implícita em um algoritmo ou nos parâmetros de um processo (uma rede neural por exemplo).
Algumas técnicas da IA podem ser classificadas tanto como simbólicas como subsimbólicas, dependendo de como a informação é encarada e codificada. Dois exemplos são as Redes de Bayes a a Lógica Fuzzy. Você pode utilizar redes bayesianas tanto para classificar padrões (subsimbólicos) como para classificar estruturas de conhecimento. Da mesma forma, uma função de pertinência em lógica difusa pode possuir um significado explícito ou pode ser simplesmente o resultado de um algoritmo numérico aplicado a um conjunto de dados.
A IA Subsimbólica tem sido tradicionalmente a área da IA mais voltada ao aprendizado automatizado. A área do Aprendizado de Máquina e seu maior cliente, o Raciocínio Baseado em Casos são a grande exceção: Aprendizado de Máquina provê um conjunto de técnicas para o aprendizado automatizado de classificadores para padrões e descrições de conhecimento e sua posterior classificação que, apesar de posuírem um certo caráter numérico, são baseadas em processos lógicos explícitos e não produzem soluções do tipo caixa preta. Em função disso, classificamos o AM como um campo da IA Simbólica.
2.1.2. Brevíssimo Histórico do Aprendizado em IA
Para você se situar, vamos, antes de entrar a fundo nesta matéria, passar uma visão histórica da origens do aprendizado em IA.
A Fase Subsimbólica (1950 - 1965)
Com muita euforia e muito otimismo foram desenvolvidos na década de 50 os primeiros sistemas computacionais capazes de aprender. Estes modelos eram baseados principalmente no modelo de neurônio de McCuloch e Pitts, de 1943, e na regra de aprendizado neuronal de Donald Hebb, de 1949, e partiam da idéia de se confeccionar sistemas capazes de aprender partir de um conjunto de informações mínimo, cuja estrutura era às vezes constituída por dados aleatórios, e a partir daí, passar a construir conhecimento aprendendo com exemplos.
A grande maioria destas primeiras "redes neurais" eram implementadas em hardware e utilizavam modelos matemáticos extremamente simplificados do que se supunha na época era a forma de funcionamento dos neurônios de um animal.
A prova, por McCulloch e Pitts, de que uma rede neural segundo o modelo por eles proposto, era capaz de representar proposições lógicas inaugurou uma euforia de desenvolvimento de diversos modelos e, mais tarde, regras de aprendizado (o modelo de McCulloch e Pitts não incluía uma regra de aprendizado).
O mais conhecido destes modelos foi o Perceptron, desenvolvido por Rosenblatt em 1958, que passou a ser utilizado para o aprendizado de diversos tipos de padrões, inclusive reconhecimento ótico de caracteres.
Subseqüentes tentativas de se extender estes modelos para tarefas mais complexas ou para o reconhecimento de padrões mais intrincados, mostraram sérias limitações nestes modelos, e em 1965 o interesse em modelos neurais foi deixando de existir e os modelos foram sendo abandonados. O ponto final nesta fase das pesquisas em aprendizado foi dado por Marvin Minsky e Seymour Papert, que em 1969 publicaram o livro Perceptrons, onde eles provam que o modelo do Perceptron é incapaz de aprender seqüências de padrões cujas classes não são linearmente separáveis. Esta prova de Minsky e Papert desestimulou tanto a comunidade de pesquisadores internacional, que pesquisas nesta área ficaram abandonadas até a invenção, por McLelland e Rummelhart, em 1984, do algoritmo Backpropagation, dando início a uma nova fase de pesquisas, numa área que viria mais tarde a ser chamada de Coneccionismo.
A grande contribuição desta primeira fase das pesquisas na área do aprendizado foi o surgimento do termo Reconhecimento de Padrões e a definição de sua área de atuação. Esta fase deixou também, na comunidade de pesquisadores, a impressão de que os métodos aprendizado de tábula-rasa eram um beco sem saída e de que a pesquisa deveria se concentrar em métodos menos simplórios.
A Fase Simbólica (1962 - 1975)
No início da década de 60, pesquisas sobre aprendizado em IA passaram a ser influenciadas por modelos cognitivos do processo de aprendizado humano. A recém surgida Psicologia Cognitiva postulava modelos do processo de percepção humano baseados na observação experimental de indivíduos e hipóteses sobre como essa percepção deveria acontecer baseadas em um modelo computacional de mente humana. Como a grande maioria dos outros campos da psicologia na época, a Psicologia Cognitiva dessa época também abstraía do funcionamento do substrato neuronal do cérebro humano, baseando-se em modelos computacionais abstratos inspirados no modelo de von Neumann, sem qualquer relação com pesquisas na Neurologia.
Vale aqui comentar que esse ponto de vista da Psicologia da época, de basear-se em modelos abstratos e ignorar completamente e de forma consciente o "hardware" da mente, o cérebro, foi na verdade uma posição filosófica da esmagadora maioria das pesquisas e dos modelos psicológicos até há bem pouco tempo atrás. Atualmente, com o surgimento de disciplinas como as Ciências Cognitivas, Neurociências e Neuropsicologia, que procuram integrar conhecimentos das áreas da Psicologia, Psiquiatria, Neurologia, Cognição e Teoria da Computação, este abismo vem se reduzindo a passos rápidos.
O termo "simbólico" desta fase do desenvolvimento de algoritmos de aprendizado, que está intimamente relacionado com o termo "explícito" em IA, significa que a interpretação dos dados ou padrões a serem aprendidos depende unicamente de informações explicitamente representadas no sistema e de regras ou conhecimento explicitamente descrito, não havendo representações de caixa-preta (como nos Perceptrons) ou representações implícitas sob a forma de algum algoritmo numérico complexo. O novo paradigma de aprendizado simbólico de conceitos utilizava, ao invés de métodos numéricos ou estatísticos, representações lógicas ou estruturadas (como grafos) de informações.
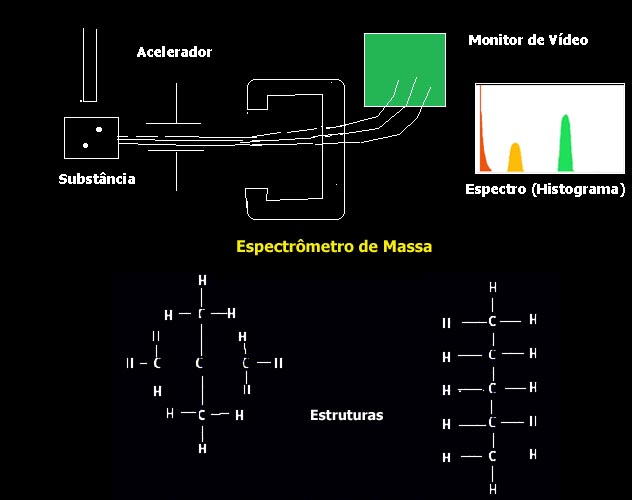
Um exemplo de um sistema de reconhecimento de padrões utilizando aprendizado dessa época é o sistema Metadendral (Buchanam, B.G., Mitchell, T.M.: Model-Directed Learning of Production Rules; in: Pattern-Directed Inference Systems, Academic Press, N.Y., 1978), capaz de aprender padrões gerados por um espectrômetro de massa (aparelho para determinar a composição química de substâncias através da composição da luz emitida por estas durante sua queima ou aquecimento). Metadendral era a componente de aprendizado do sistema especialista Dendral. Abaixo figuras representando um espectrômetro de massa e duas hipóteses de estruturas da substância entre as quais o sistema tem de decidir (adaptadas de http://web.njit.edu/~scherl/Classes/DistanceL/Ram/dendral.html).
A grande desvantagem deste paradigma foi o fato de que, para você poder implementar um sistema utilizando este enfoque, era necessário primeiro ter compreendido completamente o domínio de aplicação, para ser capaz de modelá-lo pelo menos em parte a fim de permitir o aprendizado de informações que nada mais geravam do que um ajuste fino do comportamento do sistema e não um aprendizado real de novos conceitos. Os conceitos em si já tinham de estar "programados" no sistema.
Sistemas de Aprendizado baseados em Conhecimento (1976 - 1988)
Nil posse
creari de nilo
Lucrécio, De
rerum
natura
A próxima fase teve como caracterísitcas principais o aprendizado baseado em conhecimento (em contraste com conhecimento pré-programado no sistema como no paradigma anterior) e o desenvolvimento de diferentes estratégias de aprendizado. A pesquisa não se ocupa mais de sistemas para resolver problemas específicos, mas sim de metodologias generalizadas para o aprendizado.
Os dois principais paradigmas do aprendizado de máquina, o Aprendizado Baseado em Instâncias e o Aprendizado Baseado em Modelos se estabeleceram metodologicamente nesta fase.
Um enfoque da pesquisa se concentra em grandes sistemas que são capazes de incorporar uma grande quantidade de conhecimento sobre um determinado domínio de aplicação e ser capazes de realizar raciocínios complexos neste domínio assim aprender novos fatos analisando situações. Esta área originou tanto o Raciocínio como o Aprendizado Baseado em Modelos (Model-Based Reasoning e Model-Based Learning).
Outro enfoque da pesquisa se concentrou em métodos para o suporte ao Raciocínio Indutivo, criando métodos de generalização que permitissem o aprendizado de padrões e a abstração desses padrões de forma indutiva, aprendendo as classes em que conjuntos de padrões apresentados se dividem. Esta área originou o Aprendizado Baseado em Instâncias (Instance-Based Learning), cerne de todas as pesquisas em Raciocínio Indutivo. Esta área é a área que tem o maior interesse para o Reconhecimento de Padrões pois supre métodos para o desenvolvimento de sistemas de reconhecimento de padrões com base em algoritmos simples e explícitos.
No início de década de 80, com o surgimento das primeiras conferências internacionais em AM, a área do aprendizado de máquina se estabeleceu como uma área de pesquisa independendte dentro da IA.
Sistemas Híbridos e Integrados (1988 - ...)
A tendência atual, que se iniciou em 1988 e tomou força no início da década de 90 é a pesquisa em integração de técnicas e paradigmas das diversas fases anteriores. O lado subsimbólico ganhou nova força com o renascimento da pesquisa em redes neurais e outros modelos subsimbólicos.
Uma área de grande interesse atualmente é o Aprendizado Baseado em Explicações (Explanation-Based Learning), desenvolvido por T.M. Mitchell e vários colegas em 1986, onde se procura unir aspectos subsimbólicos e simbólicos de aprendizade de máquina através de uma metodologia que utiliza raciocínio indutivo para a geração de novos conceitos e uma posterior verificação destes conceitos por métodos lógicos. A associação de um padrão a um novo conceito somente é aceita se for possível gerar-se automaticamente uma explicação plausível (p.ex. uma regra) para esta com base naquilo que foi aprendido indutivamente.
Pode-se divisar várias aplicações do ABE na área do Reconhecimento de Padrões, mas estas extrapolam o âmbito de uma disciplina de graduação e não vamos entrar em detalhes nelas aqui.
2.1.3. Como ver o aprendizado ?
O Aprendizado de Máquina na Inteligência Artificial pode ser definido da seguinte forma:
"ML - a subfield of AI that deals with techniques for improving the performance of a computational system. It is now distinguished from studies of human learning and from specific knowledge acquisition tools." (Greiner, Silver, Becker, Gruninger, A Review of Machine Learning, AAAI-87)
Vendo o aprendizado de máquina no contexto do reconhecimento de padrões, podemos, sob um ponto de vista grosseiro, imaginar o aprendizado de máquina como um método que nos permite organizar uma seqüência de exemplos de padrões P1,...,Pn em vários conjuntos de padrões CP1,...,CPk , denominados classes, de tal forma que os padrões organizados em cada conjunto são similares entre si e dissimilares dos padrões armazenados nos outros conjuntos.
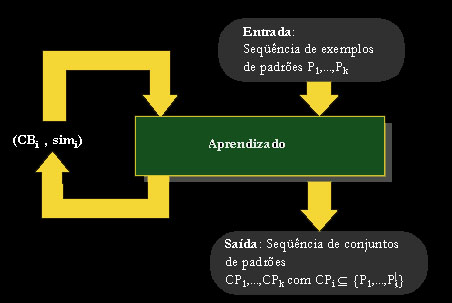
Portanto, a tarefa de aprender pode ser vista como o processo de melhora da performance de um sistema. Aprendizado de Máquina, ilustrado esquematicamente na figura acima, pode ser utilizado diferentemente:
- para a melhora dos repositórios de conhecimento de um sistema, em especial a memória de padrões (situações), através de adição, modificação e deleção de padrões,
- para a melhora da medida de similaridade (distância entre padrões), por exemplo através do ajuste de pesos, e
2.2. Classificação dos Métodos de Aprendizado
Como vimos anteriormente, ao aprender, o aprendiz (sistema de aprendizado) toma um conjunto de exemplos de situações do domínio que deve ser aprendido (padrões) e aplica um método de aprendizado para modificar seu estado interno no sentido de melhorar sua performance. Métodos de aprendizado podem ser classificados de acordo com 3 eixos:- forma de apresentação dos padrões a serem aprendidos
- processo de aprendizado
- forma de avaliação do aprendizado
2.2.1. Forma de apresentação dos padrões a serem aprendidos
Pode-se dividir de forma geral os algoritmos de aprendizado, sejam métodos estatísticos, coneccionistas ou de AM em dois grupos distintos: aqueles que realizam aprendizado supervisionado e aqueles que realizam aprendizado não supervisionado. No aprendizado supervisionado existe, embutida no método ou explicitamente representada, a figura do professor, que apresenta os exemplos a serem aprendidos e controla a avaliação da qualidade do aprendizado realizado, avaliando se um determinado conjunto de padrões de treinamento foi aprendido ou não.
Conforme vimos de maneira informal na primeira aula desta disciplina, existem, do ponto de vista do conhecimento prévio sobre o domínio de aplicação, duas categorias de problemas em reconhecimento de padrões:
- Problemas Classificatórios: Onde conhecemos o domínio de aplicação bem o suficiente e sabemos de antemão quais as classes de padrões que vão existir. O objetivo do aprendizado aqui é criar um classificador capaz de replicar este conhecimento e, eventualmente, refiná-lo. Em problemas deste tipo geralmente possuímos um conjunto de padrões pré-classificados que podemos utilizar como ponto de partida para o nosso sistema. Um exemplo citado em aula é o nosso Banco MafiaCred S.A., que possue uma coleção de descrições de clientes de empréstimos que foram atendidos nos últimos anos descritos sob a forma de vetores de pares atributo-valor e classificados como bom-pagador, médio-pagador e mau-pagador. O objetivo é integrar este conhecimento em um ssitema através de aprendizado de forma a futuramente poder utilizá-lo na classificação de novos clientes.
- Problemas Exploratórios: Onde possuímos uma coleção de padrões representando situações ou configurações de dados mas não possuímos nenhum julgamento a priori sobre estes dados: não sabemos em quantas classes este conjunto de deixa dividir nem o significado de cada padrão. O nosso objetivo aqui é justamente analisar estes dados para descobrir uma divisão statisfatória em classes, de acordo com caracteríticas dos mesmos, que ajudem a prover algum tipo de significado aos mesmos.
Para problemas exploratórios utilizamos métodos de aprendizado não supervisionado, pois queremos descobrir características implícitas nos dados que possuímos de maneira a organizá-los. No aprendizado não supervisionado os padrões do conjunto de treinamento não possuem uma pré-classificação associada pois esta é desconhecida. O objetivo do aprendizado é organizar estes dados com base em caracteríticas internas destes (coisas em comum, diferenças) de forma descobrir em quantas classes se permitem organizar, permitindo utilizar a estrutura descoberta como classificador.
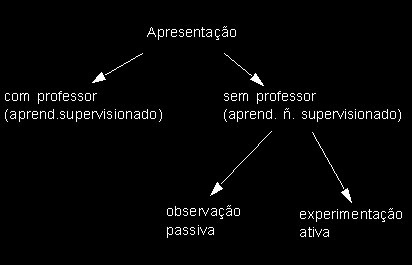
No aprendizado não supervisionado ainda temos duas subclassificações: Na observação passiva o sistema simplesmente analisa dados apresentados. Na experimentação ativa, possível de ser realizada em sistemas com algum tipo de interação com a fonte de dados (simulador, robô de medição, sistema de controle de reações químicas) o sistem apode construir hipóteses com base nos dados e testar suas conclusões.
2.2.2. Processo de aprendizado
Em todo processo de aprendizado novos conhecimentos são produzidos como conclusões deste processo. Do ponto de vista lógico, uma conclusão C pode ser sempre representada da seguinte forma:
P1, ... , Pn -> C
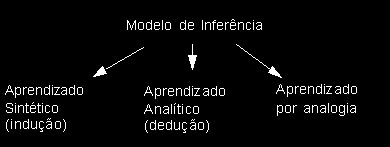
onde P1, ... , Pn são o conjunto de premissas que justificam a conclusão. Estes conhecimentos podem ser conclusões lógicas, abstrações ou analogias. Que tipo de conhecimento é gerado durante o processo de aprendizado depende do modelo de inferência subjacente ao processo. O modelo de inferência determina também a semântica de uma conclusão à qual um sistema de aprendizado chegou.
Há três modelos de inferência que podem ser seguidos: a) o aprendizado analítico, realizado por dedução, b) o aprendizado sintético, realizado por indução e c) o aprendizado por analogia, como mostra a figura abaixo:
- No aprendizado analítico são realizados raciocínios dedutivos. Aqui, tudo o que se exige para que a conclusão seja verdadeira, é que todas as premissas também sejam verdadeiras. Raciocínios dedutivos têm sido objeto principalmente de pesquisas em lógicas formais, como Lógica de Predicados, Lógica Modal, Lógica Temporal, etc. Raciocínios dedutivos são típicos em situações do tipo "Sherlock Holmes", onde possuímos conhecimento estruturado do domínio de aplicação de nosso problema e aplicamos este conhecimento para refinar nossos conhecimentos sobre uma situação específica. Raciocínios do tipo "Todo carro turbinado é veloz. Meu Lada possui um turbo. Logo meu Lada é veloz." e "Para matar a punhaladas é preciso ter acesso a um punhal. João é o único que possui um punhal. Logo João é o assassino." são exemplos de raciocínios dedutivos. Todo raciocínio dedutivo funciona de uma forma top-down, onde utilizamos um conhecimento abstrato, genérico (ex.: "Todo carro turbinado é veloz."), para provar a veracidade de premissas e assim chegar à conclusão. A dedução é uma técnica utilizada em Raciocínio Baseado em Modelos, onde modelos do domínio de aplicação nos permitem deduzir dados sobre a situação atual.
Se as premissas de uma conclusão não são absolutamente verdadeiras, mas apenas (em algum sentido qualquer) "prováveis", falamos de uma conclusão aproximada. Um exemplo de uma lógica que se utiliza de conclusões aproximadas é a Lógica Difusa (Fuzzy Logic).
Dedução dificilmente encontra aplicação em RP.
- No aprendizado sintético são realizados raciocínios indutivos, onde permitimos que fatos observados induzam a síntese de conclusões abstratas sobre a natureza do que estamos observando. A idéia básica do raciocínio indutivo é que uma conclusão C é a descrição, abstrata, geral de fenômeno que obedece a certas leis, sintetizadas através de C.
- Conceitos gerais (superconceitos) através da generalização sobre exemplos fornecidos.
- Funções sobre as quais se conhece apenas o relacionamento entre entradas e saídas, mas não a relação entre causa e efeito como regra geral de formação do efeito.
- Probabilidades para a ocorrência de determinadas situações.
A indução é geralmente o primeiro passo na descoberta de novos fenômenos naturais, antes inexplicados. Observa-se que sempre que determinada situação ocorre, determinado fenômeno é observável. Esta observação induz à conclusão de que o fenômeno está associado à situação, sem no entanto explicar a natureza desta associação. Quando realizamos pesquisa científica, normalmente partimos de um raciocínio indutivo suficientemente documentado para iniciar tentativas de encontrar leis naturais com justificativas lógicas passíveis de serem provadas. A "sabedoria de pescador" que diz que "semre que há lua cheia a maré baixa atinge seu máximo" é um exemplo de raciocínio por indução: é uma regra, corroborada pela observação (estatisticamente validada), mas que não está associada a nenhuma explicação da relação que existe entre a premissa ("lua cheia") e a conclusão ("maré é mais baixa do que em outras situações"). Todo raciocínio indutivo possui esta caracterítica estatítica: uma conclusão gerada por indução não pode ser provada, ela apenas é estatísticamente corroborada. No raciocínio indutivo, mesmo que as premissas sejam verdadeiras, a conclusão não é necessariamente verdadeira.
A uma conclusão por indução pode ser aplicado o caminho inverso através da prova da implicação das premissas por parte da conclusão através de dedução. Isto implica porém, que se necessita possuir conhecimento de domínio necessário para gerar as regras para esta prova. No caso da sabedoria de pescador do exemplo acima, sabemos, através das leis de Newton e da Astronomia, que "Quando a Terra, o Sol e a Lua se encontram alinhados, as forças de maré do Sol e da Lua se somam", sabemos também que "Quando a lua é cheia, o Sol, a Terra e a Lua estão alinhados". Com a Teoria provida por estas duas regras, podemos provar a conclusão indutiva acima, mas somente porque possuímos esta teoria.
O aprendizado sintético é o mais utilizado em RP por sua facilidade de alicação a um domínio onde o objetivo é sempre encontrar regras gerais que nos permitam classificar um conjunto de padrões cujos interrelacionamentos muitas vezes não conhcemeos de antemão.
No aprendizado sintético, pode se aprender fatos e ralacionamentos de natureza diversa. Exemplos são:
- No aprendizado por analogia a situação é um pouco diferente. Conclusões obtidas através de analogia não contam como conclusões no sentido tradicional, apesar de ocorrerem com enorme freqüência em nossso dia a dia. Aqui também vale que, mesmo que as premissas sejam verdadeiras, a conclusão não é necessariamente verdadeira. Em analogia, porém, não se objetiva gerar uma descrição ou regra absrata, apenas utilizar premissas e regras já existentes e aplicá-las a novos fatos. Aqui, o conceito de similaridade entre situações é importante.
Em RP dificilmnte utilizamos analogia.
2.2.3.
Forma
de avaliação do aprendizado
A utilização de critérios de qualidade é subjacente à idéia de aprendizado como processo de busca. Quando o objetivo do aprendizado foi atingido ou suficientemente aproximado, o processo de aprendizado pode ser terminado. A determinação do objetivo de aprendizado pode ocorrer de diferentes formas:
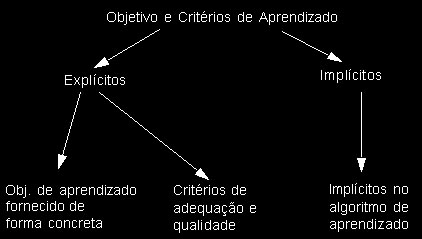
Podemos definir de forma explícita um objetivo de aprendizado quando fornecemos ao sistema as classes de padrões que queremos que aprenda.
Podemos definri critérios de qualidade quando definimos com que taxa de erro queremos que as classes que definimos sejam aprendidas, podemso também utilizar um critério de qualidade quando não sabemso quais classes existem em nosso conjunto de padrões mas definimos a taxa de erros mínima aceitável para uma classificação a ser aprendida.
Podemos também utilizar algoritmos iterativos e possuir um critério de avaliação implícito (que às vezes nada mais é do que um dos citados anteriormente).
2.2.4. Requisitos para o Reconhecimento de Padrões
Para utilizarmos algoritmos de aprendizado no campo de aplicação do reconhecimento de padrões, devemos observar as caracteríticas deste domínio de aplicação. Este possui váruias caracteríticas importantes:
- Padrões geralmente se apresentam como coleções de dados sob a forma de pares atributo-valor, onde o atributo é definido simplesmente pela posição do valor em um vetor de dados, como por exemplo no padrão: (1 2 4 11.01 1), representando a informação: (num_imóveis, num_carros, num_filhos, idade_media_filhos, bom/mau pagador)
- Os dados com que se trabalha são tipicamente dados numéricos ou representações numéricas de dados simbólicos, como por exemplo: 1=fumante, 2=não fumante, 3=fumante eventual.
- Os relacionamentos entre os dados são muitas vezes desconhecidos. Se os padrões são pré-classificados e divididos em classes, essas classes geralmente são resultado da experiência de usuários humanos no domínio de aplicação e raramente resultados da aplicação de uma teoria consistente do domínio sobre os dados.
- O nosso objetivo quase sempre será o de reconhecer padrões, ist é, de classificá-los, porém sem gerar explicações complexas sobre o porquê desta classificação.
A área do aprendizado de máquina que se ocupa com algoritmos dessa natureza é a área do Aprendizado Baseado em Instâncias.
2.3. O Aprendizado de Máquina Baseado em Instâncias
Como vimos anteriormente, em nosso breve histórico, a área do AM de maior utilidade para o reconhecimento de padrões, é a área que se ocupa com técnicas de raciocínio indutivo, conhecida como Aprendizado Baseado em Instâncias. Podemos descrevê-la bervemente como segue:
Algoritmos para o aprendizado baseado em padrões pertencem à classe de Algoritmos de Aprendizado de Instâncias, os chamados Algoritmos-IBL. Algoritmos-IBL aprendem a categorizar um conjunto de classes de objetos de forma incremental com base em exemplos de instâncias dessas categorias. Algoritmos-IBL partem do princípio que instâncias similares pertencem a categorias similares e criam essas categorias em função das similaridades detectadas.
A única entrada para algoritmos de aprendizado baseado em padrões é um conjunto de padrões de treinamento e sua saída é uma descrição de conceito que pode ser utilizada para realizar predições sobre valores de características esperados em padrões subseqüentemente apresentados.
Neste contexto, assume-se que cada padrão é representado pelo mesmo conjunto de EIs (Entidades de Informação, dados que constituem o padrão). Este conjunto de EIs define um espaço de instância n-dimensional. Exatamente uma dessas EIs corresponde ao atributo de categoria, as outras EIs são atributos preditores. Uma categoria é o conjunto de todos os casos em um espaço de instância que possue o mesmo valor para seu atributo de categoria. Aqui assumimos que existe exatamente um único atributo de categoria e que as categorias são disjuntas. Assumimos também que atributos preditores são definidos sobre conjuntos de valores completamente ordenados.
O resultado primário de algoritmos IBL é uma descrição conceitual, uma função que mapeia padrões a categorias: dado um padrão, ela proverá uma classificação que é o valor predito para o atributo de categoria deste padrão. Uma descrição conceitual baseada em instâncias inclue um conjunto de casos armazenados e possivelmente, informações sobre a sua performance classificatória no passado, como por exemplo, o número de predições classificatórias corretas e incorretas. Este conjunto de padrões pode mudar após o processamento de cada padrão de treinamento. Os conceitos estão descritos de forma implícita através da função de similaridade, da função de classificação e dos casos armazenados em uma base de padrões. Um conceito que foi aprendido não pode assim ser lido diretamente a partir da classificação de um padrão, pois ele está implícito no comportamento do sistema e não explicitamente representado. Nem o conhecimento somente da medida de similaridade nem tampouco o conhecimento somente da base de casos é suficiente para a realização do classificador. A relação da base da padrões e da medida de similaridade com um conceito a ser aprendido pode ser descrita como segue:
conceito aprendido = base de padrões + medida de similaridade
| Classes
X Categorias
Os termos Classe e Categoria são utilizados coloquialmente de forma quase sinônima. Em RBC e outras áeas que envolvem Representação de Conhecimento estas palavras representam conceitos distintos: Classe: Uma classe é um conjunto claramente definido pelos seus limites. Para toda classe existe uma definição clara de quais atributos e valores de atributos de uma instância podem pertencer à classe e quais não. A pertinência a uma classe é dada através da satisfação do conjunto desses limites. Exemplo: intervalo [95, 105], classe dos mamíferos da família dos canídeos. Categoria: Uma categoria é um conjunto definido através de um protótipo que se encontra no centro do espaço de instância que ela define. Para toda categoria há um protótipo que representa os valores típicos de uma instância desta. A pertinência a uma categoria é dada através de similaridade com o protótipo. Exemplo: categoria dos números em torno de 100, categoria dos cachorros grandes de pelo comprido. |
2.3. IBL - Instance-Based Learning: Como Algoritmos Aprendem Simbolicamente
Sempre que um sistema altera seu conhecimento de forma constante, seja através da adição de novos padrões, seja de outra forma, podemos falar de um processo de aprendizado. Enquanto que uma alteração da performance do sistema através da adição de novos padrões na base de padrões é uma estratégia geralmente aceita e muito utilizada, a alteração automatizada da medida de similaridade é menos comum.2.3.1. Componentes
Existem três componentes presentes em todas as classes de algoritmos-IBL:
- Função de similaridade. Computa a similaridade entre uma instância de treinamento i e as instâncias em uma dada descrição conceitual. Retorna valores numéricos de similaridade.
- Função de classificação. Recebe o resultado da função de similaridade e os registros de performance de classificação na descrição conceitual. Provê uma classificação para i.
- Atualizador do descritor conceitual. Mantém registro da performance classificatória e decide quais instâncias incluir na descrição conceitual. Entradas incluem i, resultados de similaridade e classificação e descrição conceitual corrente. Retorna a nova descrição conceitual.
2.3.2. Dimensões de performance
Usamos as seguintes 5 dimensões para supervisionar a performance de algoritmos de aprendizado:
- Generalidade. Representa as classes de conceitos que podem ser aprendidos e descritos pelo algoritmo em questão. IBL é capaz de aprender quaisquer conceitos cujos limites sejam dados pela união de um número finito de hipercurvas fechadas de tamanho finito.
- Acurácia. É a acurácia da classificação provida pela descrição conceitual.
- Taxa de aprendizado. É a velocidade com a qual a acurácia classificatória aumenta durante o aprendizado. É um indicador melhor de performance do que a acurácia de treinamento com um conjunto finito de exemplos.
- Custos de incorporação. Custos que decorrem da atualização da descrição conceitual através da inclusão de uma instância única. Inclue custos de classificação.
- Requisitos de armazenamento. Tamanho da descrição conceitual, que em algoritmos-IBL é definida como o número de instâncias que necessitam ser salvas para prover uma performance classificatória adequada.
O algoritmo IBL1 é o mais simples algoritmo de aprendizado baseado em instâncias. A função de similaridade é a seguinte:
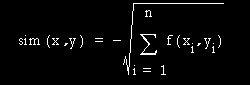
onde os casos são descritos através de n EIs. Definimos f(xi,yi) = (xi - yi)2 para EIs de valor numérico e f(xi,yi) = (xi . 1/4 yi) para EIs booleanas e de valor simbólico ou textual.
EIs ausentes são consideradas como sendo maximamente diferentes do valor presente. Se ambos faltam, então vale f(xi,yi) = 1.
IBL1 é idêntico ao algoritmo nearest neighbour, exceto pelo fato de normalizar as faixas das EIs, é capaz de processar padrões de forma incremental e possue uma política simples para lidar com valores desconhecidos.
As
funções
de similaridade e de classificação de IBL1 provêem
uma descrição conceitual extensional a partir do conjunto
de padrões salvos. Como a função de
classificação
de nearest neighbour simplesmente implementa a filosofia do vizinho
mais
próximo, pode-se determinar facilmente quais instâncias no
espaço de instância serão classificadas por qual
dos
casos armazenados. IBL1 possui uma performance relativamente boa, mas
realiza
um número desnecessário de cálculos de
similaridade
durante a predição.
 |
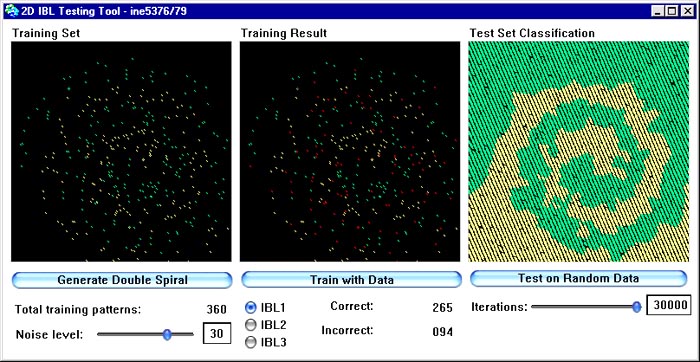
Na figura abaixo podemos observar a performance do algoritmo IBL1 para a distribuição de dados em espiral dupla. Como já foi mencionado anteriormente, a espiral dupla, onde cada braço representa uma classe, é um conjunto de dados de teste muito bom para algoritmos de aprendizado pois podemos gerá-lo artificialmente com diferentes graus de ruído e diferentes graus de detalhe e assim observar a performance de nosso algoritmo de aprendizado em diferentes condições. Além disso a espiral dupla não é um conjunto de dados lineramente separável e porisso se presta de forma excelente ao teste básico de um algoritmo de aprendizado, que é o de saber se ele é capaz de representar problemas não linearmente separáveis.
A figura representa uma implementação em Smalltalk de IBL realizada no INE/UFSC especialmente para esta disciplina, onde no primeiro campo (à esquerda) é mostrado o conjunto de dados, com uma classe em verde e outra em amarelo. No segundo campo (central) mostra-se os resultados de aprendizado de IBL, com pontos classifcados erroneamente em vermelho. No terceiro campo (à direita) é plotada a superfície de decisão gerada pelos dados armazenados na descrição conceitual aprendida por IBL1. Esta superfície de decisão e gerada através da apresentação de dados aleatórios ao algoritmo.
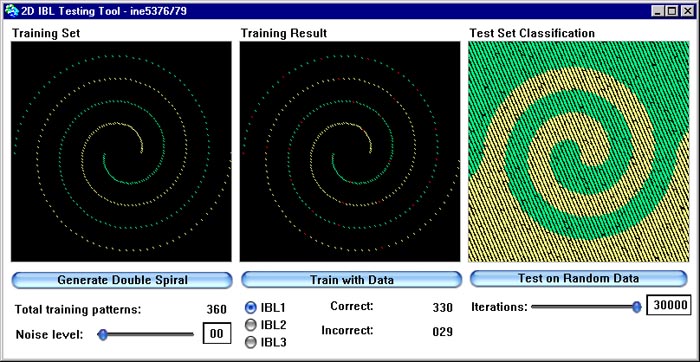
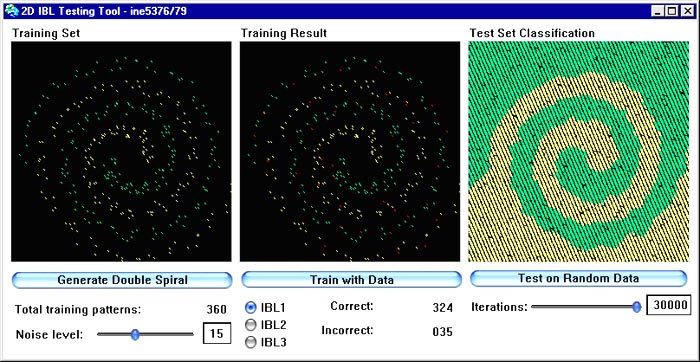
A duas próximas figuras mostram o comportamento de IBL1 com dados gerados com diferentes graus de ruído. Na primeira figura introduzimos um pouco de ruído, na segunda uma quantidade tão grande que as duas classes chegam a se misturar um pouco. Observe que IBL1 é extrememante estável na presença de ruído.
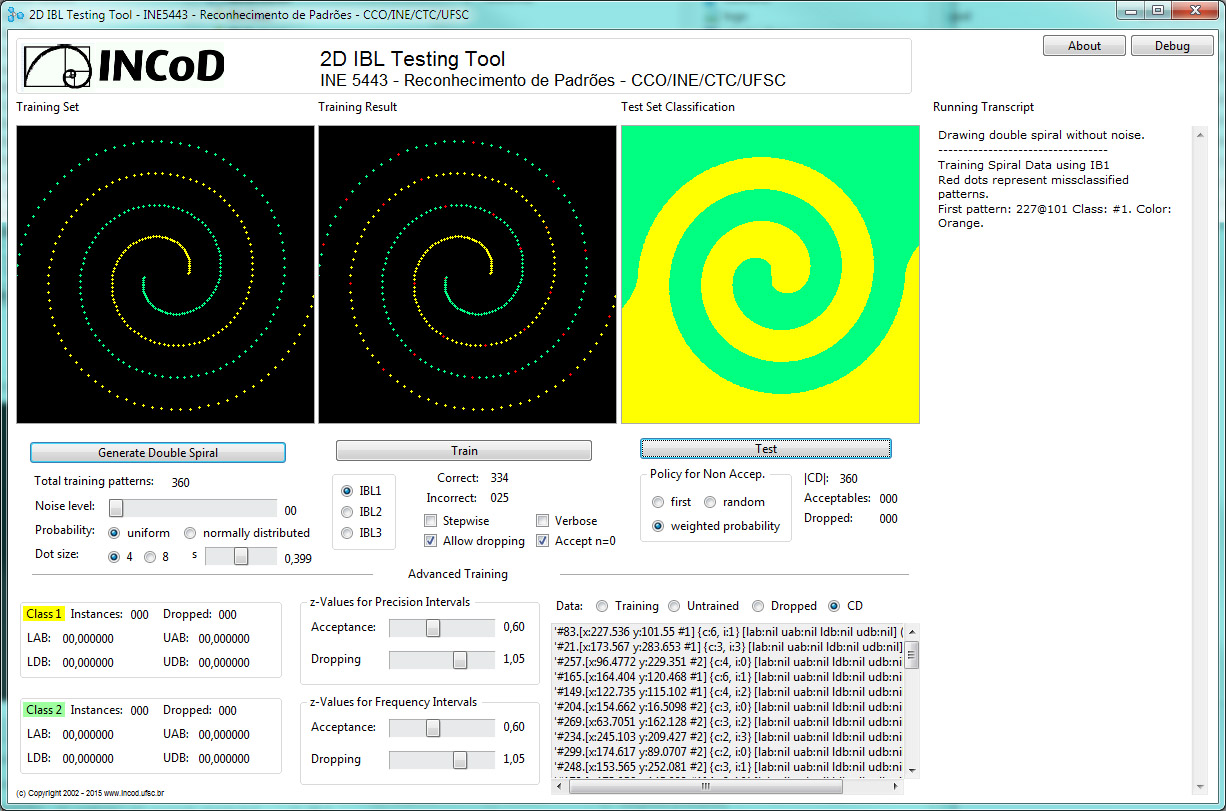
No correr da disciplina vamos estudar a família de
algoritmos IBL utilizando o IBLBrowser
a versão 2 to IBL Testing Tool disponível neste
link. Uma imagem da interface de usuário do IBLBrowser
está abaixo (clique em cima para ver melhor):
2.4. IBL2 e IBL3: Extensões do Modelo de AM
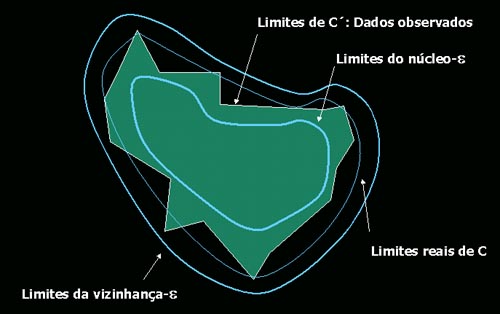
Várias extensões do algoritmo IBL foram desenvolvidas. As principais são IBL2, IBL3 e IBL4 (ainda experimental). Nesta seção vamos nos concentrar em IBL2 e IBL3 e na próxima seção discutí-los.Antes de ver estes algoritmos porém, vamos ver os conceitos de esfera-e, núcleo-e e vizinhança-e.
- esfera-e : A esfera-e em torno de um ponto x em Rn é o conjunto de pontos dentro de uma distância e de x: { y pertence a Rn | distância(x, y) < e }. Em um espaço bidimensional é um círculo.
- núcleo-e: O núcleo-e de um conjunto C é constituído por todos os pontos de C tal que a esfera-e em torno deles está contida em C.
- vizinhança-e: A vizinhança-e de C é definida como o conjunto de pontos que estão dentro de uma distância e de um ponto qualquer em C.
2.4.1. IBL2
A idéia básica de IBL2 é a de que não são necessárias todas as instâncias para permitir uma boa descrição dos limites de um conceito. De fato, necessitamos apenas dos conceitos na vizinhança dos limites do espaço deste conceito e de seu núcleo para ser utilizado como protótipo. Em outras palavras, podemos representar um conceito C armazenando apenas as instâncias que se encontram no espaço os limites do núcleo-e e da vizinhança-e. Podemos portanto economizar muito espaço armazenando apenas estes padrões.
Como este conjunto não é conhecido sem um conhecimento completo de todos os limites do conceito, ele é aproximado através das instâncias contidas em C´ e classificadas erroneamente por IBL no algoritmo IBL2. IBL2 é idêntico a IBL1, porém ele salva apenas instâncias classificadas erroneamente.
A aproximação de IBL2 é quase tão boa como a de IBL1. O raciocínio no projeto de IBL2 é o de que o que importa é termos uma representação detalhada dos limites de um conceito e que a maioria dos casos erroneamente classificados se encontram próximos às bordas deste caso no espaço de instância. IBL2 reduz drasticamente as necessidades de armazenamento.
O maior problema
de IBL2
é ruído, que rapidamente degrada sua performance, podendo
levar a uma acurácia bastante inferior à de IBL1. Isto
ocorre
porque IBL2 salva todos os exemplos de treinamento com ruído que
classifica erroneamente e depois os utiliza.
 |
Na figura abaixo podemos ver a performance de IBL2 com o mesmo conjunto de dados em espiral dupla. Observe como o conjunto de pontos aprendidos (campo central) foi drasticamente reduzido em relação a IBL1 e como as superfícies de decisão geradas se apresentam com imperfeições em relação a IBL1. A velocidade de geração destas superfícies, porém, é muito maior do que para os dados gerados por IBL1, pois o conjunto DC (descrição conceitual) é muito menor aqui do que em IBL1.
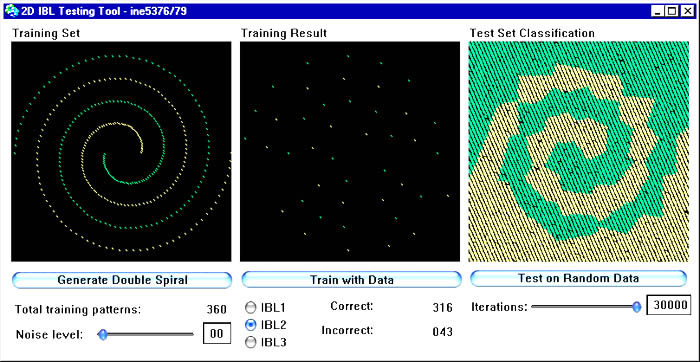
Nas próximas figura vemos o comportamento de IBL2 na presença de ruído. Aqui introduzimos ruído aleatório na geração do conjunto de treino na mesma quantidade que noos dois exemplos com ruído descritos acima para IBL1. Observe que a deterioração da qualidade é muito maior do em IBL1.
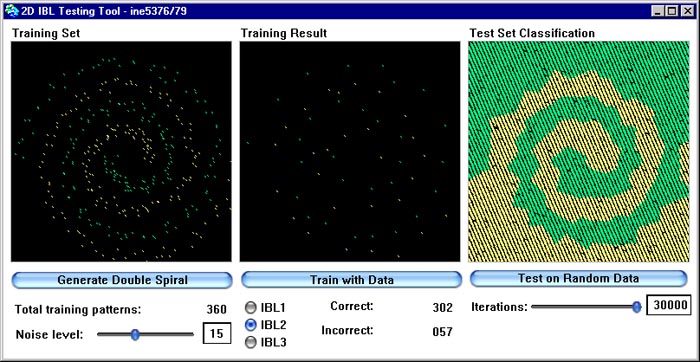
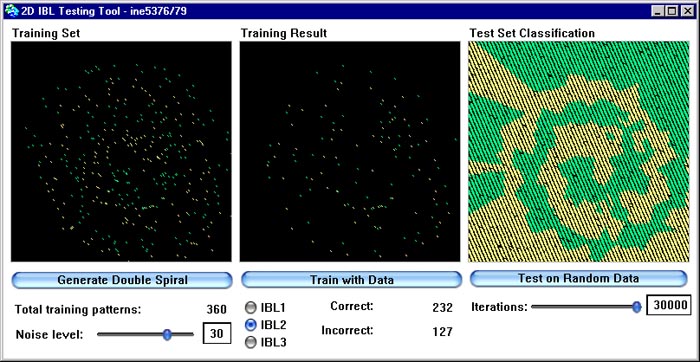
2.4.2. IBL3
IBL3 é uma extensão de IBL2 tolerante a ruídos que emprega uma estratégia de coleta de evidências de “esperar para ver” para averiguar quais das instâncias salvas vão funcionar bem durante a classificação. Sua função de similaridade é idêntica à de IBL2. Em contraste com IBL2, no entanto, IBL3 registra a freqüência com a qual um padrão armazenado, quando escolhido como o mais similar ao padrão atual, correspondeu ao valor do atributo-meta do padrão atual. A função de classificação e o algoritmo de atualização diferem em IBL3. Entre outras coisas, IBL3 mantém um registro de classificações, registrando o número de tentativas corretas e incorretas, associado a cada caso armazenado.
O registro de classificação resume a performance classificatória de um determinado padrão quando aplicado a novos padrões de treinamento e sugere como se comportará no futuro. Portanto, para cada novo padrão de treinamento apresentado, registros de classificação são atualizados para todos os padrões salvos que são tão similares ao padrão apresentado como o aceito como mais similar a este. Se nenhum dos padrões salvos é ainda suficientemente similar, é utilizada uma política que simula o comportamento do algoritmo quando pelo menos uma instância for aceitável, sendo um número randômico r gerado na faixa [1,n], onde n é o número de padrões salvos e os registros classificatórios dos r padrões salvos mais similares são atualizados. Se pelo menos um caso for aceitável, então o conjunto dos padrões salvos cujos registros classificatórios são atualizados consiste daqueles que se encontram na hiperesfera centrada no corrente caso de treinamento com raio igual à distância entre o caso corrente e o seu vizinho aceitável mais próximo.
IBL3 emprega um teste de significância para determinar quais padrões são bons classificadores e quais são supostos conterem ruído. Os primeiros são então utilizados para a classificação de padrões subseqüentemente apresentados e os outros são descartados da descrição conceitual. IBL3 aceita uma instância se a sua acurácia classificatória for significativamente superior do que a freqüência observada de sua classe e remove instâncias da descrição conceitual se sua acurácia for significativamente inferior. Intervalos de confiança para testes de proporção são utilizados para determinar se uma instância é aceitável, medíocre ou portadora de ruído. Intervalos de confiança são construídos em torno tanto da acurácia classificatória corrente da instância (taxa percentual de tentativas de classificação corretas) como da freqüência relativa observada da classe (taxa percentual de instâncias de treinamento processadas que são membro dessa classe). Se o limite inferior do intervalo de acurácia é maior do que o limite superior do intervalo de freqüência, então a instância é aceita. De forma similar, instâncias são descartadas se o limite superior de seu intervalo de acurácia for menor do que o limite inferior do intervalo de freqüência de sua classe. Se os dois intervalos não forem disjuntos, a decisão é postergada para após o treinamento.
IBL3 performa
muito melhor
do que IBL2 em domínios de aplicação com
ruído,
onde registra acurácias superiores e requisitos de armazenamento
inferiores que IBL2. Sua acurácia neste contexto é
comparável
à de IBL1. IBL3 no entanto, performa de forma ruim em
aplicações
que envolvem um grande número de atributos irrelevantes e
também
em casos onde a importância preditiva de um determinado atributo
varia de acordo com a categoria à qual um caso pertença.
 |
Imagem abaixo mostra como IBL3 rodando no IBLBrowser se comporta na presença de ruído extremo (clique sobre a imagem para ver com mais detalhes).
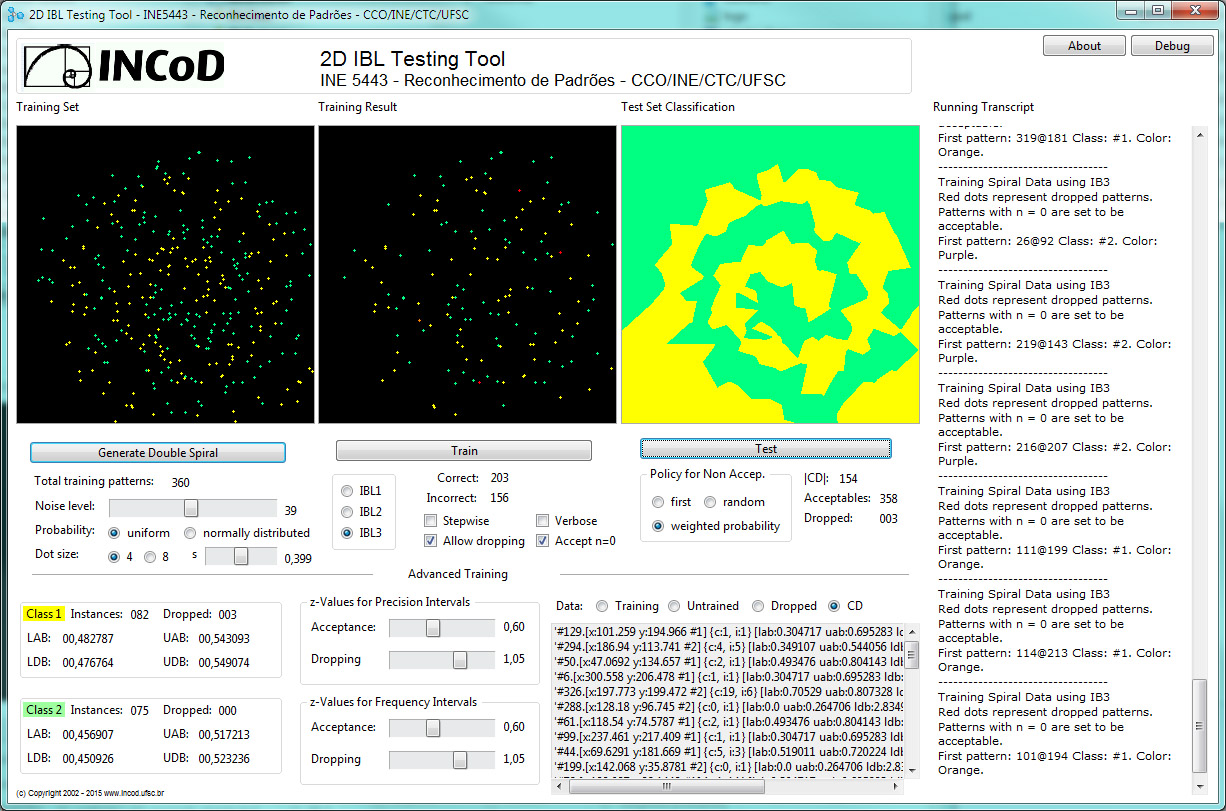
IBL3 - Comentários de Implementação
Abaixo algumas perguntas e respostas advindas da discussão de aspectos de IBL3 em aula. Uma outra visão destes aspectos é dada nas duas últimas referências de nossa bibliografia para este capítulo.Como implementar a estrutura de dados?
Inclua o registro de acertos na estrutura de dados do padrão armazenado na DC.
Como implementar aceitável(y) ?
Aceitável é suficientemente similar. Significa que a distância Sim[y] calculada com sim(x,y) deve ser menor que algum valor a de tolerância. Para isso, defina a sua tolerância como um parâmetro do algoritmo. Você pode inclusive deixar o algoritmo melhor, fazendo esta tolerância ser variável. À medida de |DC| vai ficando maior, o a pode ir sendo reduzido gradualmente. Assim no início do treinamento o algoritmo é extremamente tolerante e depois, à medida que a |DC| fica mais completa, vai ficando mais restritivo.
Para quais elementos eu atualizo o registro de classificação ?
O algoritmo sugere todos cuja similaridade seja igual a Sim[y]. Como trabalhamos com um valor real, igual é extremamente difícil de acontecer. Defina uma função equivalente(Sim[y], Sim[y2]), baseada em um parâmetro b do algoritmo, que especifica uma tolerância para esta equivalência de similaridades. Isto pode ser expresso em % e definido pelo usuário. Experimente começar com 5%.
Quais elementos eu elimino da DC ?
O algoritmo sugere todos significantemente pobres. Inicialmente, porém, acertos(y) será 0 para todos os padrões. A taxa de acertos de um padrão cresce de acordo com a inclusão de novos padrões na DC. Isto significa que padrões recém-inseridos terão taxa de acertos = 0 por um bom tempo. Para evitar a eliminação de elmentos recém incluídos, utilize um contador adicional indicando quantas vezes um elemento participou em uma rodada de classificação. Somente consideramos um elemento para eliminação se ele participou um número mínimo c de vezes. A taxa e de acertos/participação deve ser o critério de eliminação.
O que mais devo considerar na eliminação da DC ?
O número
de elementos
por classe pode ser bem diferente. Em função disso, um
número
de acertos significantemente pobre é um número que varia
de classe para classe. David Aha sugere que se calcule a taxa
relativa
de acertos de um elemento para tomar essa decisão: n°
de acertos do elemento / n° de elementos na classe.
Isto significa que o algoritmo necessita de uma lista adicional
contendo
o número de elementos de cada classe, atualizada sempre que um
novo
elemento é incluído. Faça o limiar de
eliminação
c
ser essa taxa, caso seja
a participação
do padrão em classificações seja maior que um
limiar.
2.5. Discussão de AM e IBL
O aprendizado baseado em instâncias favorece o aprendizado incremental a partir da experiência, uma vez que é sempre mais fácil aprender através da retenção da memória de uma experiência concreta do que generalizar a partir dela.Esta é uma importante vantagem para o desenvolvimento de aplicações, pois permite a sistemas iniciar sua operação com um pequeno conjunto de padrões e a adicionar cobertura através do armazenamento de novos padrões se for demonstrado que são necessários. Como não realiza nenhum tipo de generalização do conhecimento, não incorre no risco de esquecer detalhes à medida que o conhecimento cresce.
Algoritmos do
tipo IBL possuem
um custo de atualização relativamente reduzido e o
aprendizado
baseado em instâncias permite o uso de algoritmos bastante
robustos,
que podem manipular dados incompletos ou com ruído praticamente
em tempo real.
Além disso,
sistemas
com aprendizado IBL são verificáveis (o que não se
pode dizer da maioria dos modelos de redes neuronais, por exemplo),
pois
permitem que se consulte os padrões concretos
responsáveis
pelo comportamento classificatório adquirido pelo sistema
após
o aprendizado.
Do ponto de vista
matemático,
todos os algoritmos da família IBL incrementalmente aprendem
aproximações
parcialmente lineares de conceitos em um espaço n-dimensional
através
da medida de similaridade baseada em nearest neighbour, o que é
uma forma bastante natural de se aproximar uma grande gama de
distribuições
de variáveis. Por outro lado, isto torna o método ruim
para
representar variáveis dadas por funções não
lineares muito complexas
2.7. Referências e links úteis
2.7.1. Referências BibliográficasExiste pouca bibliografia que trata de forma sistemática o Aprendizado de Máquina. Abaixo quatro referências comentadas:
v.Wangenheim, Ch.G. e v.Wangenheim, A.: Retenção de Novos Casos in: Raciocínio Baseado em Casos, Editora Manole, Curitiba, Brasil, pp. 219 - 236, 2002.
Neste livro sobre RBC abordamos o assunto do aprendizado indutivo de padrões e casos no capítulo 9. Este capítulo serve também como referência sobre o assunto de AM, pois esta técnica é a técnica tradicionalmente utilizada no aprendizado de novos casos em RBC.Wendel, O. e Richter, M.M.: Lernende Sisteme I - Symbolische Methoden. Universitätsdruckerei der Univeristät Kaiserslautern, Kaiserslautern, Alemanha, 151 pp., 1992.
Esta é a apostila (em alemão...) da cadeira Sistemas de Aprendizado I do curso de ciências da computação da Universidade de Kaiserlsautern, Alemanha. É o melhor e didaticamente mais bem organizado material que o autor conhece sobre o assunto AM. Cópias podem ser adquiridas através do endereço de contato disponível em http://wwwagr.informatik.uni-kl.de ou através de contato direto com o autor, Prof. Dr. Michael M. Richter (richter@informatik.uni-kl.de).D. RANDALL WILSON, TONY R. MARTINEZ: Reduction Techniques for Instance-Based Learning Algorithms. Machine Learning, vol. 38, pp. 257-286, 2000.
Neste artigo os autores discutem os algoritmos existentes para redução das necessidades de armazenamento de métodos da família IBL através da otimização da escolha de candidatos ao aprendizado e apresentam uma nova família de algoritmos também com essa finalidade.
Flávia
Oliveira
Santos, Maria do Carmo Nicoletti: A
Família de Algoritmos Instance-Based Learning ( IBL ).
Relatório
Técnico Universidade Federal de São Carlos (UFSCar),
Departamento
de Computação (DC).
Este relatório apresenta e discute os algoritmos IB2, IB3, IB4 e IB5. Uma raríssima referência em português sobre o assunto. Bastante bem escrito.
2.7.2. Links
Úteis
Para compensar a falta de livros sobre o assunto, na Internet encontramos muitas referências sobre AM. Sem dúvida a melhor fonte de informação é a página sobre Aprendizado de Máquina de David Aha: David Aha's list of machine learning resources. Neste site você vai encontrar também uma página dedicada a implementações open source de algoritmos de AM, principalmente a família IBL (incluindo IBL4): http://www.aic.nrl.navy.mil/~aha/software/index.html
Além do
site de David
Aha existe ainda uma infinidade de material disponível sobre AM.
Sugerimos que você olhe na página de links
do site desta disciplina para ver mais.
|
The Cyclops
Project
German-Brazilian Cooperation Programme on IT CNPq GMD DLR |

