The following learning parameters (from left to right) are used by the learning functions that are already built into SNNS:
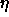 : learning parameter, specifies the step width of the
gradient descent.
: learning parameter, specifies the step width of the
gradient descent.
Typical values of 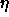 are
are 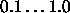 . Some small examples
actually train even faster with values above 1, like 2.0.
. Some small examples
actually train even faster with values above 1, like 2.0.
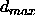 : the maximum difference
: the maximum difference
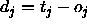 between a teaching value
between a teaching value 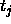 and
an output
and
an output 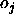 of an output unit which is tolerated,
i.e. which is propagated back as
of an output unit which is tolerated,
i.e. which is propagated back as 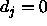 .
If values above 0.9 should be regarded as 1 and values
below 0.1 as 0, then
.
If values above 0.9 should be regarded as 1 and values
below 0.1 as 0, then 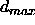 should be set to
should be set to 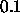 .
This prevents overtraining of the network.
.
This prevents overtraining of the network.
Typical values of 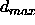 are 0, 0.1 or 0.2.
are 0, 0.1 or 0.2.
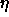 : learning parameter, specifies the step width of the
gradient descent.
: learning parameter, specifies the step width of the
gradient descent.
Typical values of 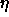 are
are 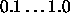 . Some small examples
actually train even faster with values above 1, like 2.0.
. Some small examples
actually train even faster with values above 1, like 2.0.
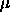 : momentum term, specifies the amount of the old weight
change (relative to 1) which is added to the current change.
: momentum term, specifies the amount of the old weight
change (relative to 1) which is added to the current change.
Typical values of 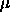 are
are 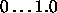 .
.
Typical values of c are 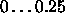 , most often
0.1 is used.
, most often
0.1 is used.
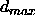 : the maximum difference
: the maximum difference
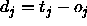 between a teaching value
between a teaching value 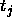 and
an output
and
an output 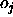 of an output unit which is tolerated,
i.e. which is propagated back as
of an output unit which is tolerated,
i.e. which is propagated back as 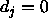 . See above.
. See above.
The general formula for Backpropagation used here is
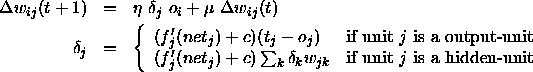
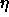 : learning parameter, specifies the step width of the
gradient descent.
: learning parameter, specifies the step width of the
gradient descent.
Typical values of 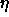 are
are 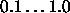 . Some small examples
actually train even faster with values above 1, like 2.0.
. Some small examples
actually train even faster with values above 1, like 2.0.
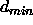 : the minimum weight that is tolerated for a
link. All links with a smaller weight will be pruned.
: the minimum weight that is tolerated for a
link. All links with a smaller weight will be pruned.
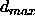 : the maximum difference
: the maximum difference
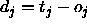 between a teaching value
between a teaching value 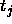 and
an output
and
an output 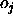 of an output unit which is tolerated,
i.e. which is propagated back as
of an output unit which is tolerated,
i.e. which is propagated back as 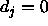 . See above.
. See above.
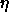 : learning parameter, specifies the step width of the
gradient descent.
: learning parameter, specifies the step width of the
gradient descent.
Typical values of 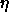 for BPTT and BBPTT are
for BPTT and BBPTT are 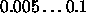 .
.
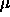 : momentum term, specifies the amount of the old weight
change (relative to 1) which is added to the current change.
: momentum term, specifies the amount of the old weight
change (relative to 1) which is added to the current change.
Typical values of 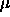 are
are 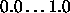 .
.
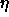 : learning parameter, specifies the step width of the
gradient descent.
: learning parameter, specifies the step width of the
gradient descent.
Typical values of 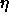 for Quickprop are
for Quickprop are 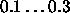 .
.
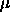 : maximum growth parameter, specifies the maximum amount
of weight change (relative to 1) which is added to the current change
: maximum growth parameter, specifies the maximum amount
of weight change (relative to 1) which is added to the current change
Typical values of 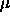 are
are 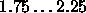 .
.
 : weight decay term to shrink the weights.
: weight decay term to shrink the weights.
Typical values of  are
are 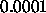 . Quickprop is rather
sensitive to this parameter. It should not be set too large.
. Quickprop is rather
sensitive to this parameter. It should not be set too large.
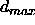 : the maximum difference
: the maximum difference
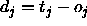 between a teaching value
between a teaching value 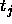 and
an output
and
an output 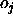 of an output unit which is tolerated,
i.e. which is propagated back as
of an output unit which is tolerated,
i.e. which is propagated back as 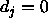 . See above.
. See above.
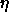 : learning parameter, specifies the step width of the
gradient descent.
: learning parameter, specifies the step width of the
gradient descent.
Typical values of 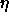 for QPTT are
for QPTT are 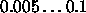 .
.
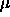 : maximum growth parameter, specifies the maximum amount
of weight change (relative to 1) which is added to the current change
: maximum growth parameter, specifies the maximum amount
of weight change (relative to 1) which is added to the current change
Typical values of 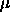 are
are 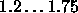 .
.
 : weight decay term to shrink the weights.
: weight decay term to shrink the weights.
Typical values of  are
are 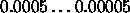 .
.
The largest backstep value supported is 10.
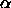 : learning parameter of the Kohonen layer.
: learning parameter of the Kohonen layer.
Typical values of 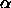 for Counterpropagation are
for Counterpropagation are 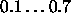 .
.
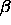 : learning parameter of the Grossberg layer.
: learning parameter of the Grossberg layer.
Typical values of 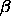 are
are 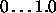 .
.
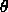 : threshold of a unit.
: threshold of a unit.
We often use a value 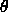 of 0.
of 0.
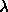 : global error magnification. This is the factor in
the formula
: global error magnification. This is the factor in
the formula 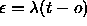 , where
, where  is
the internal activation error of a unit, t is the teaching
input and o the output of a unit.
is
the internal activation error of a unit, t is the teaching
input and o the output of a unit.
Typical values of 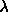 are 1. Bigger values (up to 10)
may also be used here.
are 1. Bigger values (up to 10)
may also be used here.
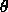 : If the error value
: If the error value 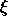 drops below this threshold
value, the adaption according to the Backpercolation algorithm
begins.
drops below this threshold
value, the adaption according to the Backpercolation algorithm
begins. 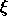 is defined as:
is defined as:
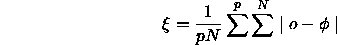
 : the maximum difference
: the maximum difference
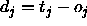 between a teaching value
between a teaching value 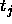 and
an output
and
an output 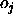 of an output unit which is tolerated,
i.e. which is propagated back as
of an output unit which is tolerated,
i.e. which is propagated back as 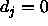 . See above.
. See above.
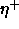 : learning rate, specifies the step width of the mean
vector
: learning rate, specifies the step width of the mean
vector 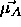 , which is nearest to a pattern
, which is nearest to a pattern 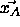 ,
towards this pattern. Remember that
,
towards this pattern. Remember that 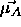 is moved only, if
is moved only, if
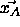 is not assigned to the correct class
is not assigned to the correct class 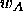 . A typical
value is 0.03.
. A typical
value is 0.03.
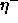 : learning rate, specifies the step width of a mean
vector
: learning rate, specifies the step width of a mean
vector 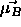 , to which a pattern of class
, to which a pattern of class 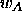 is falsely
assigned to, away from this pattern. A typical value is 0.03. Best
results can be achieved, if the condition
is falsely
assigned to, away from this pattern. A typical value is 0.03. Best
results can be achieved, if the condition 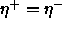 is
satisfied.
is
satisfied.
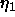 used for the
modification of center vectors.
used for the
modification of center vectors.
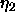 , used for
the modification of the parameters p of the base function. p
is stored as bias of the hidden units.
, used for
the modification of the parameters p of the base function. p
is stored as bias of the hidden units.
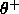 : positive threshold. To commit a new prototype,
none of the existing RBFs of the correct class may have an
activation above
: positive threshold. To commit a new prototype,
none of the existing RBFs of the correct class may have an
activation above 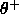
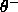 :negative threshold. During shrinking no RBF unit of
a conflicting class is allowed to have an activation above
:negative threshold. During shrinking no RBF unit of
a conflicting class is allowed to have an activation above
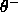 .
.
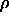 : vigilance parameter. If the quotient of active F
: vigilance parameter. If the quotient of active F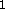 units
divided by the number of active F
units
divided by the number of active F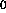 units is below
units is below 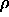 , an
ART reset is performed.
, an
ART reset is performed.
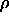 : vigilance parameter. Specifies the minimal length of the
error vector r (units
: vigilance parameter. Specifies the minimal length of the
error vector r (units 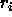 ).
).
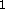 by
the middle level.
by
the middle level.
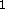 by
the upper level.
by
the upper level.
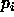 ) used to compute the error.
) used to compute the error.
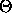 : Threshold for output function f of units
: Threshold for output function f of units 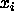 and
and
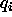 .
.
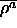 : vigilance parameter for
: vigilance parameter for 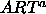 subnet.
(quotient
subnet.
(quotient 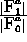 )
)
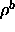 : vigilance parameter for
: vigilance parameter for 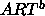 subnet.
(quotient
subnet.
(quotient 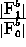 )
)
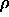 : vigilance parameter for inter ART reset control.
(quotient
: vigilance parameter for inter ART reset control.
(quotient 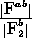 )
)
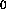 : starting values for all
: starting values for all 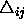 .
Default value is 0.1.
.
Default value is 0.1.
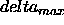 : the upper limit for the update values
: the upper limit for the update values
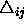 .The default value of
.The default value of 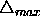 is
is 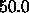 .
.
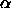 : the weight-decay determines the relationship
between the output error and to reduction in the size of the
weights. Important: Please note that the weight decay
parameter
: the weight-decay determines the relationship
between the output error and to reduction in the size of the
weights. Important: Please note that the weight decay
parameter 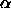 denotes the exponent, to allow comfortable
input of very small weight-decay. A choice of the third
learning parameter
denotes the exponent, to allow comfortable
input of very small weight-decay. A choice of the third
learning parameter 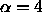 corresponds to a ratio of
weight decay term to output error of
corresponds to a ratio of
weight decay term to output error of 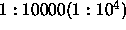 .
.
CC and RCC are not learning functions themselves. They are meta algorithms to build and train optimal networks. However, they have a set of standard learning functions embedded. Here these functions require modified parameters. The embedded learning functions are:
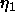 : learning parameter, specifies the step width of gradient
decent minimizing the net error.
: learning parameter, specifies the step width of gradient
decent minimizing the net error.
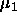 : momentum term, specifies the amount of the old weight
change, which is added to the current change.
: momentum term, specifies the amount of the old weight
change, which is added to the current change.
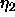 : learning parameter, specifies the step width of gradient
ascent maximizing the covariance.
: learning parameter, specifies the step width of gradient
ascent maximizing the covariance.
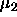 : momentum term specifies the amount of the old weight change,
which is added to the current change.
: momentum term specifies the amount of the old weight change,
which is added to the current change.
The general formula for this learning function is:
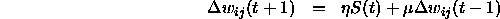
The slopes 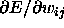 and
and 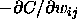 are abbreviated by S. This abbreviation is valid for all embedded functions.
By changing the sign of the gradient value
are abbreviated by S. This abbreviation is valid for all embedded functions.
By changing the sign of the gradient value 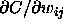 ,
the same learning function can be used to maximize the covariance and to
minimize the error.
,
the same learning function can be used to maximize the covariance and to
minimize the error.
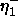 : decreasing factor, specifies the factor by which
the update-value
: decreasing factor, specifies the factor by which
the update-value 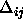 is to be decreased when minimizing the
net error. A typical value is
is to be decreased when minimizing the
net error. A typical value is 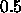 .
.
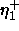 : increasing factor, specifies the factor by which
the update-value
: increasing factor, specifies the factor by which
the update-value 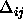 is to be increased when minimizing the
net error. A typical value is
is to be increased when minimizing the
net error. A typical value is 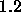
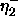 : decreasing factor, specifies the factor by which
the update-value
: decreasing factor, specifies the factor by which
the update-value 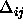 is to be decreased when maximizing the
covariance. A typical value is
is to be decreased when maximizing the
covariance. A typical value is 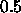 .
.
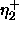 : increasing factor, specifies the factor by which
the update-value
: increasing factor, specifies the factor by which
the update-value 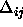 is to be increased when maximizing the
covariance. A typical value is
is to be increased when maximizing the
covariance. A typical value is 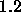
The weight change is computed by:
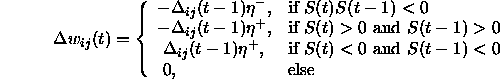
where 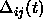 is defined as follows:
is defined as follows: 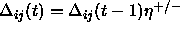 . Furthermore, the condition
. Furthermore, the condition 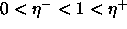 should not be violated.
should not be violated.
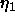 : learning parameter, specifies the step width of the
gradient descent when minimizing the net error.
A typical value is
: learning parameter, specifies the step width of the
gradient descent when minimizing the net error.
A typical value is 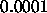
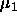 : maximum growth parameter, realizes a kind of dynamic
momentum term. A typical value is 2.0.
: maximum growth parameter, realizes a kind of dynamic
momentum term. A typical value is 2.0.
 : weight decay term to shrink the weights. A typical value is
: weight decay term to shrink the weights. A typical value is
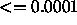 .
.
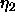 : learning parameter, specifies the step width of the
gradient ascent when maximizing the covariance.
A typical value is
: learning parameter, specifies the step width of the
gradient ascent when maximizing the covariance.
A typical value is 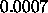
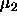 : maximum growth parameter, realizes a kind of dynamic
momentum term. A typical value is 2.0.
: maximum growth parameter, realizes a kind of dynamic
momentum term. A typical value is 2.0.
The formula used is:
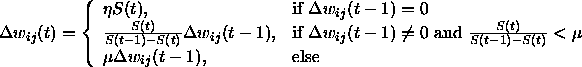
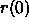 is the radius of the neighborhood of the winning unit. All
units within this radius are adapted. Values should range between 1
and the size of the map.
is the radius of the neighborhood of the winning unit. All
units within this radius are adapted. Values should range between 1
and the size of the map.
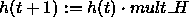
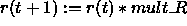
NOTE: With this learning rule the update function RM_Synchronous has to be used which needs as update parameter the number of iterations!
 .
.
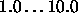 .
.
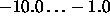 .
.
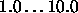 .
.
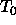 : learning parameter, specifies the Simulated Annealing
start temperature .
Typical values of
: learning parameter, specifies the Simulated Annealing
start temperature .
Typical values of 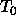 are
are 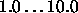 .
.
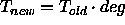 Typical values of deg are
Typical values of deg are 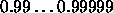 .
.
All of the following parameters are non-critical, i.e. they influence only the speed of convergence, not whether there will be success or not.
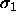 . Should satisfy
. Should satisfy 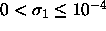 . If 0, will
be set to
. If 0, will
be set to 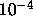 ;
;
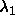 . Should satisfy
. Should satisfy 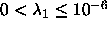 . If 0,
will be set to
. If 0,
will be set to 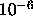 ;
;
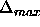 . See standard backpropagation. Can be set to 0 if
you don't know what to do with it;
. See standard backpropagation. Can be set to 0 if
you don't know what to do with it;
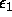 . Depends on the floating-point precision. Should be set to
. Depends on the floating-point precision. Should be set to
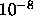 (simple precision) or to
(simple precision) or to 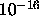 (double precision). If
0, will be set to
(double precision). If
0, will be set to 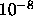 .
.