 |
|
|
|
Vamos aqui ver na prática como o bubblesort se comporta com diferentes conjuntos de dados. Esta página também servirá de exemplo de como os trabalhos de implementação de Quick- e Heapsort dados em aula deverão ser executados.
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <sys/timeb.h>
FILE *gnuplot;
inline void swap (double a[], int i, int j)
{
double temp = a[i];
a[i] = a[j];
a[j] = temp;
}
void bubble(double a[], int N)
{
int i, j;
for (i=N; i >= 0; i--)
for (j = 1; j <= i; j++)
if (a[j-1] > a[j]) swap(a, j-1, j);
}
void leia( char *nome )
{
double *a, *ptr;
struct timeb tempoInicial, tempoFinal;
int i, tamanho;
FILE *arquivo;
arquivo = fopen(nome, "r");
fscanf(arquivo, "%d", &tamanho);
a = malloc(tamanho * sizeof(double));
printf("%d\t\t", tamanho);
fprintf( gnuplot, "%d\t\t", tamanho);
for (i=1; i <= tamanho; i++)
{
fscanf(arquivo, "%d", &a[i-1]);
}
/*-------------------*/
ftime( &tempoInicial );
bubble( a, tamanho - 1);
ftime( &tempoFinal );
/*-------------------*/
free(a);
fprintf( gnuplot," %d \n", tempoFinal.time - tempoInicial.time );
printf(" %d \n", tempoFinal.time - tempoInicial.time );
fclose(arquivo);
}
Observe que o cálculo do tempo de ordenação (as duas
chamadas a ftime()) não leva em conta o tempo necessário
para ler os dados. Isto pode parecer meio ingênuo, mas o que nós
queremos é somente saber como o algoritmo de ordenação
em si se comporta e não quanto tempo outras operações
de inicialização vão levar.
main()
{
system("clear");
gnuplot = fopen("bubb-rnd.dat", "w");
printf("RANDOMICOS\nTamanho \t Tempo\n");
fprintf(gnuplot, "#RANDOMICOS\n#Tamanho \t Tempo\n");
leia ("rnd10.dat");
leia ("rnd50.dat");
leia ("rnd100.dat");
leia ("rnd500.dat");
leia ("rnd1000.dat");
leia ("rnd2000.dat");
leia ("rnd5000.dat");
leia ("rnd10000.dat");
fclose(gnuplot);
gnuplot = fopen("bubb-ord.dat", "w");
printf("\nORDENADOS\nTamanho \t Tempo\n");
fprintf(gnuplot, "#ORDENADOS\n#Tamanho \t Tempo\n");
leia ("ord10.dat");
leia ("ord50.dat");
leia ("ord100.dat");
leia ("ord500.dat");
leia ("ord1000.dat");
leia ("ord2000.dat");
leia ("ord5000.dat");
leia ("ord10000.dat");
fclose(gnuplot);
gnuplot = fopen("bubb-inv.dat", "w");
printf("\nINVERSAMENTE ORDENADOS\nTamanho \t Tempo\n");
fprintf(gnuplot, "#INVERSAMENTE ORDENADOS\n#Tamanho \t Tempo\n");
leia ("inv10.dat");
leia ("inv50.dat");
leia ("inv100.dat");
leia ("inv500.dat");
leia ("inv1000.dat");
leia ("inv2000.dat");
leia ("inv5000.dat");
leia ("inv10000.dat");
fclose(gnuplot);
gnuplot = fopen("bubb-prc.dat", "w");
printf("\nPARCIALMENTE ORDENADOS\nTamanho \t Tempo\n");
fprintf(gnuplot, "#PARCIALMENTE ORDENADOS\n#Tamanho \t Tempo\n");
leia ("prc10.dat");
leia ("prc50.dat");
leia ("prc100.dat");
leia ("prc500.dat");
leia ("prc1000.dat");
leia ("prc2000.dat");
leia ("prc5000.dat");
leia ("prc10000.dat");
fclose(gnuplot);
gnuplot = fopen("bubb-piv.dat", "w");
printf("\nPARCIALMENTE INVERSAMENTE ORDENADOS\nTamanho \t Tempo\n");
fprintf(gnuplot, "#PARCIALMENTE INVERSAMENTE ORDENADOS\n#Tamanho \t Tempo\n");
leia ("piv10.dat");
leia ("piv50.dat");
leia ("piv100.dat");
leia ("piv500.dat");
leia ("piv1000.dat");
leia ("piv2000.dat");
leia ("piv5000.dat");
leia ("piv10000.dat");
fclose(gnuplot);
system("gnuplot -bg gray90 plota.gnu");
}
Assim, os resultados de operação do Bubblesort para até 10.000 dados sao dados no gráfico GnuPlot abaixo: Observe que, ao contrário do que seria de se esperar, o estado inicial dos dados (randômicos, ordenados, invertidos, etc) não parece afetar muito o tempo de ordenação. As diferencas são realmente bastante pequenas, embora uma performance um pouco maior com dados já ordenados possa ser notada se olhamos com atenção.
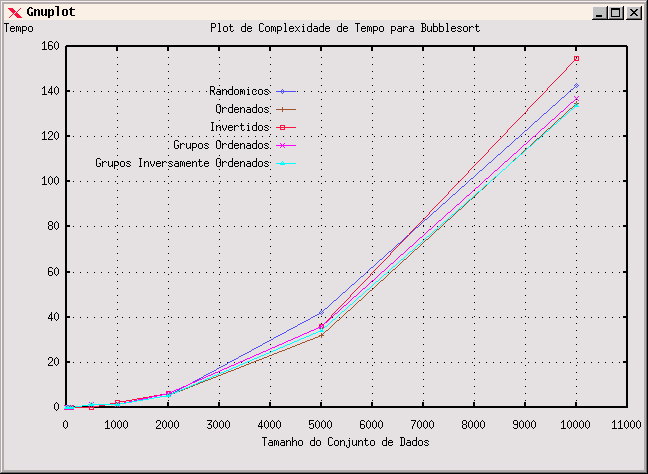
Isto está em conflito com a nossa noção intuitiva de que, uma vez que o bubblesort trabalha invertendo dados adjacentes fora de ordem, se os dados já estão em ordem, ele deveria trabalhar MUITO mais rápido, já que ele nesse caso não move nada.
Essa noção com certeza está correta, o que nós não levamos em conta e que o custo da operacão de troca triangular implementada pela função swap() tem um custo relativo bastante baixo se a compararmos aos dois laços para-faça que serão executados de qualquer forma e para todos os dados.
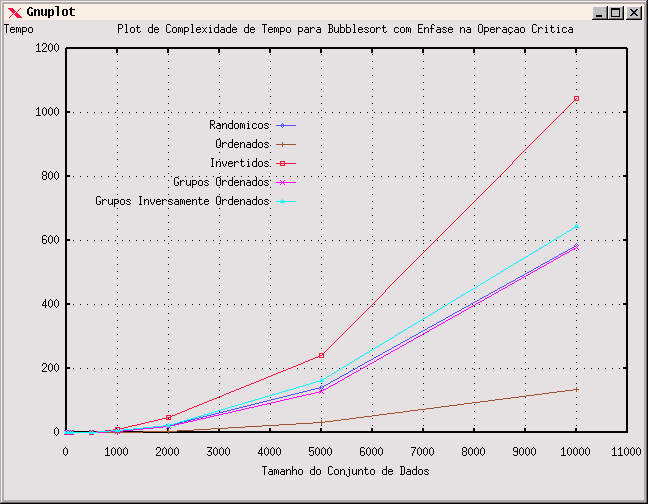
Nós podemos forçar uma situação diferente, definindo a função swap() como uma operação crítica e fazendo-a ter um custo bastante alto. Podemos fazer isto artificialmente simplesmente colocando um laço para-faça vazio dentro do swap, como abaixo:
inline void swap (double a[], int i, int j)
{
long temp2;
double temp = a[i];
a[i] = a[j];
a[j] = temp;
for (temp2=1; temp2 < 200; temp2++);
}
Se o fizermos assim, estaremos simulando uma "dificuldade" maior em trocar
os dados de lugar do que simplesmente lê-los e compará-los
(lembre-se: a comparação é realizada nos testes dos
laços). Podemos imaginar uma situação real onde isto
ocorre se imaginarmos um disco onde escrever um dado noutro lugar demora
bastante, simplesmente lê-lo não. O resultado que obtemos
então, corresponde muito mais à nossa noção
intuitiva:
Eles estão organizados em cinco diferentes grupos:
| Números completamente aleatórios | rnd.zip |
| Números totalmente ordenados | ord.zip |
| Números ordenados em ordem inversa | inv.zip |
| Números organizados em grupos de números
ordenados em ordem crescente. O primeiro elemento de cada grupo, porém, é sempre escolhido ao acaso. |
prc.zip |
| Números organizados em grupos de números
ordenados em ordem decrescente. O primeiro elemento de cada grupo é também sempre escolhido ao acaso. |
piv.zip |
A idéia do nosso teste é ver se os algoritmos que estamos
implementando possuem um comportamento uniforme para dados organizados
de qualquer forma ou se para dados organizados de forma "pouco natural",
como é o caso de todos os conjuntos de arquivos com exceção
do primeiro.
| A forma como os dados estão armazenados em cada arquivo
é simples: a primeira linha contém o número de elementos que o arquivo contém. Daí para baixo estão os elementos, um por linha. O arquivo de saída que o seu programa deverá produzir
terá de
Não pode ser uma linha. |
Exemplo: arquivo bubb-ord.dat produzido pelo Bubble. Comentários são iniciados por um # #ORDENADOS #Tamanho Tempo 11 0 51 0 101 0 501 1 1001 1 2001 5 5001 32 10001 135 |
Para que a formatação de tela seja bonitinha como você com certeza vai querer, é interessante que um arquivo de comandos gnuplot seja enviado ao gnuplot além dos arquivos de dados. Este arquivo está exemplificado aqui abaixo (para os dados do bubble). Lembre-se de produzir arquivos de saída com os mesmos nomes do exemplo dado acima ou então de mudar o seu arquivo de comando gnuplot.
# ---------------------------------------------------------- # Arquivo de comandos GnuPlot para a plotagem da curva de # Complexidade de Tempo do Algoritmo Bubblesort (Ordenacao # Por Bolha). # # Este programa GnuPlot seta uma janela grafica e le varios # arquivos de dados. # ---------------------------------------------------------- set title "Plot de Complexidade de Tempo para Bubblesort" # #Seta tamanho da janela automaticamente de acordo com os dados set autoscale set data style linespoints set xlabel "Tamanho do Conjunto de Dados" set ylabel "Tempo" # #Seta posicao em coordenadas dos dados, onde vao aparecer os titulos #Ist voce DEVE adaptar aos seus dados set key 4000, 140 # #Seta grade set grid # # Le arquivos e plota dados plot \ "bubb-rnd.dat" title "Randomicos" w linespoints 3,\ "bubb-ord.dat" title "Ordenados" w linespoints 6, \ "bubb-inv.dat" title "Invertidos" w linespoints 1, \ "bubb-prc.dat" title "Grupos Ordenados", \ "bubb-piv.dat" title "Grupos Inversamente Ordenados" # # Para que voce possa chamar o gnuplot diretamente de dentro de seu # programa em C usando o comando system(). Se voce nao colocar uma # pausa no final de seu plot, a janela fecha imediatamente apos # ter sido desenhada. pause -1 "Tecle enter para sair..."